ASCII (American Standard Code for Information Interchange) — американский стандарт кодирования символов, разработанный для обмена текстовой информацией между устройствами и программами. В таблице определено 128 позиций (0-127), где каждой букве, цифре, знаку препинания или управляющей команде соответствует числовое значение.
Этот стандарт стал универсальной системой представления текста в цифровом виде и заложил фундамент для всех последующих кодировок, включая Unicode. Его принципы до сих пор применяются в операционных системах, языках программирования и сетевых протоколах.
ASCII описывает систему, где каждый символ представлен числовым кодом. Компьютеры оперируют не знаками, а числами, поэтому кодировка обеспечивает взаимопонимание между устройствами.
Пример числовых соответствий:
-
A — 65
-
a — 97
-
пробел — 32
-
0 — 48
Благодаря единой таблице любой символ читается одинаково на разных платформах. Этот принцип стал ключевым для развития вычислительной техники и сетевых коммуникаций.
Краткая суть и значение в истории IT
Появление ASCII стало поворотным моментом в истории ИТ. До его утверждения каждый производитель применял собственные таблицы символов, из-за чего данные, переданные с одного устройства, могли отображаться некорректно на другом.
ASCII впервые установил единые правила, сделав возможным массовый обмен информацией между несовместимыми ранее системами. Этот шаг превратил текст в универсальную форму данных и стал основой для развития телекоммуникаций, программирования и компьютерных сетей.
История появления
ASCII возник не как случайное изобретение, а как необходимость — ответ на стремительное развитие телекоммуникаций и вычислительной техники середины XX века. Переход от аналоговой связи к цифровой требовал унифицированного языка, который понимали бы и машины, и операторы. Этот язык должен был быть простым, компактным и пригодным для любых устройств, от телетайпов до первых компьютеров.
Контекст 1960-х
В послевоенные годы активно использовались телетайпы — электромеханические машины, способные печатать сообщения, передаваемые по телефонным линиям. Они заменяли телеграф и использовались в армии, авиации, банках и редакциях газет. Каждая модель имела собственный набор кодов: Baudot, Murray, ITA2, позднее — внутренние таблицы производителей вроде Western Electric или Teletype Corporation.
Такая разрозненность вызывала постоянные ошибки: одни и те же байты трактовались как разные символы, данные терялись или искажались.
К началу 1960-х стало очевидно, что требуются единые стандарты передачи текстовой информации. К этому времени появлялись первые компьютеры, но обмен данными между ними был сложен именно из-за несовместимости кодировок. Кроме того, необходимо было задать не только буквы и цифры, но и управляющие команды, такие как возврат каретки, перевод строки или сигнал завершения передачи. Всё это подтолкнуло инженеров и производителей к созданию общего системного языка символов.
Американская ассоциация стандартов (ASA) сформировала специальный комитет X3.4, куда вошли представители компаний IBM, AT&T, Honeywell и Bell Labs. Их задачей было определить набор символов, достаточный для любых коммуникаций, но при этом компактный, чтобы помещался в байт данных — восемь бит. Первые проекты включали больше 200 символов, однако для простоты систему сократили до 128.
Организация ANSI и принятие стандарта
После нескольких лет обсуждений в 1963 году была опубликована первая спецификация ASCII. В документе определялись:
-
числовые коды для латинских букв, цифр и основных знаков препинания;
-
управляющие символы (NUL, LF, CR, ESC и другие);
-
структура таблицы — 7-битная, что обеспечивало совместимость с восьмибитными системами, где один бит использовался для контроля ошибок.
В 1967 году стандарт получил официальное утверждение от ANSI (American National Standards Institute), сменившего ASA. В 1968 году добавлены последние элементы — вертикальная черта «|» и тильда «~». Этот набор в дальнейшем практически не менялся и используется в неизменном виде до сих пор.
Принятие ASCII совпало с формированием первых компьютерных сетей — ARPANET и коммерческих телекоммуникационных линий. Появился реальный инструмент для унификации обмена текстом между различными вычислительными системами, независимо от производителя и архитектуры.
Кроме того, ASCII стал частью международного стандарта ISO 646, что позволило адаптировать его для разных стран: в национальных версиях некоторые символы заменялись (например, знак доллара на фунт в британском варианте), но основа оставалась общей.
ASCII стал своего рода «латинским алфавитом» для машин — простым, понятным и универсальным языком коммуникации.
Распространение и применение
После стандартизации ASCII быстро получил признание индустрии. Он стал основой для развития операционных систем и языков программирования.
В 1970-е годы кодировка внедряется в UNIX, язык C и большинство терминалов того времени. Команды, системные сообщения и текстовые интерфейсы опирались исключительно на ASCII.
Вскоре таблица ASCII стала обязательным элементом компьютерной архитектуры:
-
микропроцессоры Intel, DEC и Motorola изначально проектировались с учётом ASCII-кодировки;
-
принтеры и модемы использовали её при передаче текстовых данных;
-
протоколы связи (SMTP, FTP, HTTP) строились на текстовых командах, составленных из ASCII-символов.
Например, строки заголовков в письмах электронной почты или HTTP-запросах до сих пор передаются в виде обычного ASCII-текста, что гарантирует читаемость на любых устройствах.
Принципы кодирования в ASCII
Любая система обработки данных опирается на способ представления информации в виде чисел. Для компьютера текст — это не набор букв, а совокупность бинарных значений, которые он может хранить, передавать и преобразовывать. Кодировка ASCII устанавливает строгие правила соответствия между символами и их числовыми кодами. Этот подход обеспечивает однозначность интерпретации данных и совместимость между различными устройствами и программами.
Почему символы кодируются числами
Цифровые устройства оперируют двоичными значениями (0 и 1). Чтобы компьютер мог обрабатывать текст, символы должны быть представлены в числовом виде. Таблица ASCII задаёт соответствие между символом и его числом. Например, буква A соответствует двоичному коду 01000001.
Системы представления
Один и тот же символ можно выразить в трёх формах:
-
Двоичная: 01000001
-
Десятичная: 65
-
Шестнадцатеричная: 41
Двоичный вид понятен машине, десятичный — человеку, а шестнадцатеричный удобен при отладке и анализе.
Управляющие и печатные символы
Первые 32 кода (0–31) — управляющие. Они не имеют графического отображения и используются для сигналов «перевод строки», «звонок», «возврат каретки» и т. д.
Коды 32–126 — печатные символы: буквы, цифры и знаки препинания. Код 127 — DEL, удаление символа.
Такое разделение позволило описывать не только текст, но и процессы его вывода на экран или печать.
Структура таблицы ASCII
Таблица ASCII построена таким образом, чтобы распределение кодов отражало функциональное значение символов. Порядок не случаен: управляющие коды идут первыми, за ними — пробел, цифры, буквы и специальные знаки. Такое расположение облегчает сортировку, поиск, редактирование и работу с текстом в программном обеспечении. Благодаря логичной структуре таблица остаётся удобной для анализа даже спустя десятилетия после создания.
Деление на диапазоны
Разница между регистрами
Заглавные и строчные буквы различаются на 32 единицы в десятичной системе. Это свойство используется в программах для преобразования регистра:
Такое упорядочение упрощает сортировку и поиск по алфавиту.
Расширения ASCII
Со временем базового диапазона ASCII стало недостаточно. Развитие международных вычислительных систем и увеличение числа языков, использующих нелатинские алфавиты, потребовали расширения набора символов. Стандарт из 128 позиций покрывал только английский язык и основные знаки препинания, что ограничивало его применимость в глобальной среде. При этом сохранялась необходимость совместимости со старыми системами, поэтому разработчики выбрали путь расширения таблицы, а не создания нового стандарта.
Extended ASCII
Базовый диапазон 0–127 был дополнен новыми символами, образовав 8-битный набор 0–255. Расширенные версии получили общее название Extended ASCII. Они включали буквы с диакритикой, символы национальных алфавитов, графические и служебные элементы.
Наиболее распространённые варианты:
-
ISO 8859-1 (Latin-1) — охватывает языки Западной Европы;
-
Windows-1252 — версия Microsoft с типографскими кавычками, знаком евро и дополнительными символами;
-
Mac Roman — использовалась в старых операционных системах Apple.
Ключевым принципом расширенных кодировок стала обратная совместимость: первые 128 позиций полностью совпадали с оригинальной таблицей ASCII. Это гарантировало корректную работу старых программ при обработке новых текстов.
Однако появление множества вариаций породило новую проблему — несовместимость между ними. Один и тот же байт в разных кодировках мог обозначать разные символы, что приводило к искажению текста при передаче между системами. Например, код 0x80 в Windows-1252 соответствует типографской кавычке, а в ISO 8859-1 не используется вовсе. Эта ситуация сделала невозможным создание единой международной текстовой среды.
Национальные варианты
В разных странах появились собственные расширения.
-
В СССР и России — KOI8-R и CP866, обеспечивавшие поддержку кириллицы;
-
В Восточной Европе — ISO 8859-2 для польского, чешского и венгерского языков;
-
В Азии — локальные кодировки для японского, китайского и корейского письма.
Несмотря на адаптацию к национальным алфавитам, эти кодировки не были совместимы между собой. Один и тот же документ мог отображаться по-разному на разных устройствах, что усложняло международный обмен данными.
Ограничения
Расширенные наборы отличались расположением символов и правилами интерпретации байтов. Один код мог обозначать разные буквы в разных системах, что делало невозможным универсальную обработку текстов. Эта проблема стала главным стимулом для перехода к универсальному стандарту Unicode, охватывающему все письменности мира и сохраняющему совместимость с ASCII в первых 128 кодах.
ASCII в программировании
ASCII — базовая кодировка для большинства языков программирования. Любой символ можно преобразовать в число и обратно:
В языке C:
Эти функции используются при обработке строк, шифровании, анализе протоколов и разработке терминальных интерфейсов.
Escape-последовательности
Управляющие символы в программировании записываются через обратный слэш:
- \n — перевод строки (LF, код 10);
- \r — возврат каретки (CR, код 13);
- \t — табуляция (TAB, код 9);
- \b — шаг назад (BS, код 8).
Эти комбинации позволяют форматировать текст при выводе и управлять позиционированием курсора.
ASCII в практике
Несмотря на появление Unicode и множества современных кодировок, ASCII продолжает использоваться в тысячах программных и аппаратных систем по всему миру. Его простота, минимальные требования к ресурсам и абсолютная совместимость делают стандарт идеальным для базового обмена текстовой информацией. ASCII остаётся неотъемлемой частью архитектуры сетевых протоколов, операционных систем, микроконтроллеров и конфигурационных файлов.
В большинстве случаев именно ASCII лежит в основе служебных структур данных, системных логов и коммуникаций между устройствами.
Применение в системах
-
Текстовые файлы — базовые форматы .txt, .ini, .cfg, .log и конфигурационные документы используют только ASCII-символы, что обеспечивает их универсальное чтение в любой среде.
-
Сетевые протоколы — команды, заголовки и ответы в HTTP, SMTP, FTP, POP3, IMAP оформляются в виде строк ASCII, что гарантирует читаемость и стабильность работы протоколов на разных платформах.
-
Терминалы и консоли — интерфейсы UNIX, Linux и Windows CMD передают команды и результаты выполнения в ASCII-потоках, обеспечивая совместимость между оболочками и удалёнными серверами.
-
Встраиваемые системы — микроконтроллеры, промышленные контроллеры и IoT-устройства хранят параметры и диагностические данные в текстовом ASCII-формате для упрощения отладки и взаимодействия с инженерным ПО.
ASCII art и креативные применения
ASCII применяется и за пределами программирования. Художники создают изображения, используя символы как пиксели. Примеры таких работ используются в логотипах, баннерах, ретро-играх и генераторах текста. Этот вид искусства сохраняет популярность благодаря минимализму и совместимости с любым терминалом.
ASCII и Unicode
Развитие компьютерных систем и рост глобальных коммуникаций потребовали кодировки, способной охватывать не только латиницу, но и все мировые письменности. К началу 1990-х годов стало очевидно, что набор ASCII, включающий всего 128 символов, не справляется с этой задачей. Возникла потребность в универсальном стандарте, объединяющем национальные алфавиты и технические символы, но при этом совместимом с уже существующими системами.
Так появился Unicode — логическое продолжение ASCII, расширившее его принципы до глобального масштаба. Unicode стал основой современной цифровой коммуникации, сохранив при этом преемственность с оригинальным стандартом.
Отличия и совместимость
Unicode — расширение идей ASCII. В нём предусмотрено более двух миллионов кодовых позиций, охватывающих все известные письменности, математические и технические знаки, пиктограммы и эмодзи. Первые 128 кодов полностью совпадают с таблицей ASCII, что обеспечивает полную обратную совместимость.
Кодировки UTF-8, UTF-16 и UTF-32 реализуют разные способы хранения символов Unicode в памяти и передаче данных. Наиболее распространённой стала UTF-8, так как она сохраняет однобайтовое представление для символов ASCII и использует больше байтов только при необходимости.
Почему Unicode не вытеснил ASCII
Несмотря на универсальность Unicode, ASCII остаётся востребованным в областях, где важны простота, стабильность и минимальный размер данных.
Преимущества ASCII:
-
минимальный размер символа — 1 байт;
-
высокая скорость обработки;
-
совместимость с устаревшими и встроенными протоколами;
-
устойчивость на всех платформах и в любых языках программирования.
Unicode применяется для многоязычных систем, веб-приложений и документов, где требуется поддержка различных алфавитов. ASCII продолжает использоваться в базовых служебных структурах, системном программировании, логах, сетевых заголовках и текстовых протоколах, где производительность и надёжность важнее универсальности.
Таблица символов ASCII (0–127)
Эта таблица образует минимальный набор символов, поддерживаемый всеми системами без исключения.
Преимущества и ограничения ASCII
После десятилетий использования ASCII остаётся одним из самых устойчивых стандартов в сфере информационных технологий. Его принципы просты, но именно эта простота обеспечила долговечность и совместимость с современными системами. При этом у стандарта есть объективные пределы, обусловленные историческими ограничениями его разработки. Рассмотрим сильные стороны и недостатки ASCII с позиции современного ИТ-контекста.
Преимущества
-
Простая структура и лёгкая реализация.
-
Полная совместимость между устройствами, операционными системами и протоколами.
-
Небольшой объём данных — каждый символ занимает 1 байт.
-
Надёжность и устойчивость при передаче информации в любых сетях.
-
Базовая совместимость с Unicode и его подмножествами (первые 128 кодов полностью совпадают).
Благодаря этим свойствам ASCII до сих пор используется как внутренний формат системных утилит, терминалов, микроконтроллеров и текстовых протоколов, где минимализм и предсказуемость критически важны.
Ограничения
-
Всего 128 символов — недостаточно для национальных алфавитов и расширенных наборов знаков.
-
Отсутствие поддержки диакритики, символов валют, графических элементов и специальных обозначений.
-
Невозможность прямого применения в многоязычных и контентных системах.
-
Проблемы совместимости при переходе на расширенные версии и другие локальные кодировки.
Несмотря на это, ASCII остаётся основой большинства современных текстовых форматов. Такие технологии, как HTML, XML, JSON, CSV, используют ASCII в качестве базового слоя представления данных, а Unicode — лишь как надстройку для дополнительных символов. Это доказывает, что даже в эпоху глобальных стандартов минимализм ASCII продолжает обеспечивать стабильность цифрового обмена.
<!DOCTYPE html>
<html class="h-100" data-bs-theme="light" data-mantine-color-scheme="light" lang="ru" prefix="og: https://ogp.me/ns#">
<head>
<meta content="width=device-width, initial-scale=1.0" name="viewport">
<meta content="IE=Edge" http-equiv="X-UA-Compatible">
<link crossorigin="true" href="https://cdn.hexlet.io" rel="preconnect">
<link href="https://mc.yandex.ru" rel="preconnect">
<meta content="aa2vrdtq64dub8knuf83lwywit311w" name="facebook-domain-verification">
<link href="/favicon.ico" rel="icon" sizes="any">
<link href="/favicon.svg" rel="icon" type="image/svg+xml">
<link href="/apple-touch-icon.png" rel="apple-touch-icon">
<link href="/manifest.webmanifest" rel="manifest">
<script>
//<![CDATA[
window.gon={};gon.ym_counter="25559621";gon.is_bot=true;gon.applications={};gon.current_user={"id":null,"last_viewed_notification_id":null,"email":null,"state":null,"first_name":"","last_name":"","created_at":"2026-02-26 20:44:01 UTC","current_program":null,"current_team":null,"full_name":"","guest":true,"can_use_paid_features":false,"is_hexlet_employee":false,"sanitized_phone_number":"","can_subscribe":true,"can_renew_education":false};gon.token="6RLcruq-Z61vaW_FoFqI9q4n3golurcvCxHxikJJFT4GwxeZGMDKzdkqS12sVXiBbi7zoC2NSY228WveEE7yUA";gon.locale="ru";gon.language="ru";gon.theme="light";gon.rails_env="production";gon.mobile=false;gon.google={"analytics_key":"UA-1360700-51","optimize_key":"GTM-5QDVFPF"};gon.captcha={"google_v3_site_key":"6LenGbgZAAAAAM7HbrDbn5JlizCSzPcS767c9vaY","yandex_site_key":"ysc1_Vyob5ZPPUdPBsu0ykt8bVFdzsfpoVjQChLGl2b4g19647a89","verification_failed":null};gon.social_signin=false;gon.typoreporter_google_form_id="1FAIpQLSeibfGq-KvWQ2Fyru-zkFFRVTLBuzXAHAoEyN1p49FtDmNoNA";
//]]>
</script>
<meta charset="utf-8">
<title>Что такое ASCII? — Q&A Хекслет</title>
<meta name="description" content="2 ответа на вопрос, что такое ASCII простыми словами? Глоссарий Хекслета.">
<link rel="canonical" href="https://ru.hexlet.io/qna/glossary/questions/chto-takoe-ascii">
<meta property="og:description" content="2 ответа
на вопрос, что такое ASCII простыми словами? Глоссарий Хекслета.">
<meta property="og:title" content="Что такое ASCII? — Q&A Хекслет">
<meta property="og:url" content="https://ru.hexlet.io/qna/glossary/questions/chto-takoe-ascii">
<meta name="csrf-param" content="authenticity_token" />
<meta name="csrf-token" content="o7F4sKc_4s94j10PuBc3qEHq6O_HabkM31x-8sxIY-NMYLOHVUFPr87MeZe0GMffgePFRc9eR65ivOSmnk-EjQ" />
<script src="/vite/assets/inertia-DfXos102.js" crossorigin="anonymous" type="module"></script><link rel="modulepreload" href="/vite/assets/chunk-DsPFFUou.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/preload-helper-BJ4cLWpC.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/init-BrRXra1y.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/ahoy-DrlRQ-1D.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/analytics-cb8xch9l.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/ErrorFallbackBlock-naDSYSy9.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/Surface-DL2bpZA-.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/gon-D3e4yh1x.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/mantine-CGMYrt2Y.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/utils-DRqSHbQE.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/routes-CCH8ilKF.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/extends-C-EagtpE.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/inheritsLoose-BBd-DCVI.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/objectWithoutPropertiesLoose-DRHXDhjp.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/index.esm-DAqKOkZ0.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/Button-CGPUux8l.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/CloseButton-D1euiPao.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/Group-BX48WcuU.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/Loader-BQEY8g6v.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/Modal-Cy3HByv7.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/OptionalPortal-1Hza5P2w.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/Stack-CtjJzfw4.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/Textarea-Ck64llAy.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/Box-B5-OOzBf.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/DirectionProvider-Dc9zdUke.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/events-DJQOhap0.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/use-reduced-motion-D2owz4wa.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/use-disclosure-zKtK5W1r.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/use-hotkeys-Cnc_Rwkb.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/random-id-DOQyszCZ.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/notifications.store-C-3AFSMn.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/exports-C_MrNx_T.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/axios-BEvgo0ym.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/dayjs.min-BkKovM-s.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/i18next-BlSq9s7B.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/client-U9M77rxp.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/react-dom-DaLxUz_h.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/useTranslation-Bx1Cdrkz.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/compiler-runtime-6XxiPFnt.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/jsx-runtime-CwjcCKJi.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/react-CkL4ZRHB.js" as="script" crossorigin="anonymous">
<link rel="stylesheet" href="/vite/assets/application-BqhCP46M.js" />
<script src="/vite/assets/application-Df9RExpe.js" crossorigin="anonymous" type="module"></script><link rel="modulepreload" href="/vite/assets/chunk-DsPFFUou.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/autocomplete-VMNbxKGl.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/routes-CCH8ilKF.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/createPopper-C3aM9r1M.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/js.cookie-D1-O8zkX.js" as="script" crossorigin="anonymous"><link rel="stylesheet" href="/vite/assets/application-C8HjmMaq.css" media="screen" />
<script>
window.ym = function(){(ym.a=ym.a||[]).push(arguments)};
window.addEventListener('load', function() {
setTimeout(function() {
ym.l = 1*new Date();
ym(window.gon.ym_counter, "init", {
clickmap: true,
trackLinks: true,
accurateTrackBounce: true,
webvisor: true
});
// Загружаем скрипт
var k = document.createElement('script');
k.async = 1;
k.src = 'https://mc.yandex.ru/metrika/tag.js';
document.head.appendChild(k);
ym(window.gon.ym_counter, 'getClientID', function(clientID) {
window.ymClientId = clientID;
});
}, 1500);
});
</script>
<!-- Google Tag Manager - deferred -->
<script>
// dataLayer stub сразу — пуши работают до загрузки скрипта
window.dataLayer = window.dataLayer || [];
// Сам скрипт — отложенно после load
window.addEventListener('load', function() {
setTimeout(function() {
dataLayer.push({'gtm.start': new Date().getTime(), event: 'gtm.js'});
var j = document.createElement('script');
j.async = true;
j.src = 'https://www.googletagmanager.com/gtm.js?id=GTM-WK88TH';
document.head.appendChild(j);
}, 1500);
});
</script>
<!-- End Google Tag Manager -->
</head>
<body>
<noscript>
<div>
<img alt="" src="https://mc.yandex.ru/watch/25559621" style="position:absolute; left:-9999px;">
</div>
</noscript>
<header class="sticky-top bg-body">
<nav class="navbar navbar-expand-lg">
<div class="container-xxl">
<a class="navbar-brand" href="/"><img alt="Логотип Хекслета" height="24" src="https://ru.hexlet.io/vite/assets/logo_ru_light-BpiEA1LT.svg" width="96">
</a><button aria-controls="collapsable" aria-expanded="false" aria-label="Меню" class="navbar-toggler border-0 mb-0 mt-1" data-bs-target="#collapsable" data-bs-toggle="collapse">
<span class="navbar-toggler-icon"></span>
</button>
<div class="collapse navbar-collapse" id="collapsable">
<ul class="navbar-nav mb-lg-0 mt-lg-1">
<li class="nav-item dropdown">
<button aria-haspopup class="btn nav-link" data-bs-toggle="dropdown" type="button">
Все курсы
<span class="bi bi-chevron-down align-middle ms-1"></span>
</button>
<ul class="dropdown-menu">
<li>
<a class="dropdown-item d-flex py-2" href="/courses"><div class="fw-bold me-auto">Все что есть</div>
<div class="text-muted">117</div>
</a></li>
<li>
<hr class="dropdown-divider">
</li>
<li class="dropdown-item">
<b>Популярные категории</b>
</li>
<li>
<a class="dropdown-item py-2" href="/courses_devops">Курсы по DevOps
</a></li>
<li>
<a class="dropdown-item py-2" href="/courses_data_analytics">Курсы по аналитике данных
</a></li>
<li>
<a class="dropdown-item py-2" href="/courses_programming">Курсы по программированию
</a></li>
<li>
<a class="dropdown-item py-2" href="/courses_testing">Курсы по тестированию
</a></li>
<li>
<hr class="dropdown-divider">
</li>
<li class="dropdown-item">
<b>Популярные курсы</b>
</li>
<li>
<a class="dropdown-item py-2" href="/programs/devops-engineer-from-scratch">DevOps-инженер с нуля
</a></li>
<li>
<a class="dropdown-item py-2" href="/programs/go">Go-разработчик
</a></li>
<li>
<a class="dropdown-item py-2" href="/programs/java">Java-разработчик
</a></li>
<li>
<a class="dropdown-item py-2" href="/programs/python">Python-разработчик
</a></li>
<li>
<a class="dropdown-item py-2" href="/programs/qa-auto-engineer-java">Автоматизатор тестирования на Java
</a></li>
<li>
<a class="dropdown-item py-2" href="/programs/data-analytics">Аналитик данных
</a></li>
<li>
<a class="dropdown-item py-2" href="/programs/frontend">Фронтенд-разработчик
</a></li>
</ul>
</li>
<li class="nav-item dropdown">
<button aria-haspopup class="btn nav-link" data-bs-toggle="dropdown" type="button">
О Хекслете
<span class="bi bi-chevron-down align-middle"></span>
</button>
<ul class="dropdown-menu bg-body">
<li>
<a class="dropdown-item py-2" href="/pages/about">О нас
</a></li>
<li>
<a class="dropdown-item py-2" href="/blog">Блог
</a></li>
<li>
<span class="dropdown-item py-2 external-link" data-href="https://special.hexlet.io/hse-research" role="button">Результаты (Исследование)
</span></li>
<li>
<span class="dropdown-item py-2 external-link" data-href="https://career.hexlet.io" role="button">Хекслет Карьера
</span></li>
<li>
<a class="dropdown-item py-2" href="/testimonials">Отзывы студентов
</a></li>
<li>
<span class="dropdown-item py-2 external-link" data-href="https://t.me/hexlet_help_bot" role="button">Поддержка (В ТГ)
</span></li>
<li>
<span class="dropdown-item py-2 external-link" data-href="https://special.hexlet.io/referal-program/?promo_creative=priglasite-druzei&promo_name=referal-program&promo_position=promo_position&promo_start=010724&promo_type=link" role="button">Реферальная программа
</span></li>
<li>
<span class="dropdown-item py-2 external-link" data-href="https://special.hexlet.io/certificate" role="button">Подарочные сертификаты
</span></li>
<li>
<span class="dropdown-item py-2 external-link" data-href="https://hh.ru/employer/4307094" role="button">Вакансии
</span></li>
<li>
<span class="dropdown-item d-flex external-link" rel="noopener noreferrer nofollow" data-href="https://b2b.hexlet.io" data-target="_blank" role="button">Компаниям
</span></li>
<li>
<span class="dropdown-item d-flex external-link" rel="noopener noreferrer nofollow" data-href="https://hexly.ru/" data-target="_blank" role="button">Колледж
</span></li>
<li>
<span class="dropdown-item d-flex external-link" rel="noopener noreferrer nofollow" data-href="https://hexlyschool.ru/" data-target="_blank" role="button">Частная школа
</span></li>
</ul>
</li>
<li><a class="nav-link" href="/subscription/new">Подписка</a></li>
</ul>
<ul class="navbar-nav flex-lg-row align-items-lg-center gap-2 ms-auto">
<li>
<a class="nav-link" aria-label="Переключить тему" href="/theme/switch?new_theme=dark"><span aria-hidden="true" class="bi bi-moon"></span>
</a></li>
<li>
<span data-target="_self" class="nav-link external-link" data-href="/u/new" role="button"><span>Регистрация</span>
</span></li>
<li>
<span data-target="_self" class="nav-link external-link" data-href="https://ru.hexlet.io/session/new" role="button"><span>Вход</span>
</span></li>
</ul>
</div>
</div>
</nav>
</header>
<div class="x-container-xxxl">
</div>
<main class="mb-6 min-vh-100 h-100">
<link rel="preload" as="image" href="https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6NDAyOCwicHVyIjoiYmxvYl9pZCJ9fQ==--ae9eed98663dd1201759d042a5ba7ca790866156/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Programming-bro.png"/><link rel="preload" as="image" href="https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6MzY2MSwicHVyIjoiYmxvYl9pZCJ9fQ==--e9c2b6bde361adaac625a7f47d8b9671c17f3ddb/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Mathematics-bro.png"/><link rel="preload" as="image" href="https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6MzcyNywicHVyIjoiYmxvYl9pZCJ9fQ==--2d5cbbf5c3b4a73ae4b2c50632305d78f5872e4d/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Programmer-rafiki.png"/><link rel="preload" as="image" href="https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6NDAzNCwicHVyIjoiYmxvYl9pZCJ9fQ==--ba516ea9573bdfcd1d21e2aa0fff8818561828f2/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Typing-bro.png"/><link rel="preload" as="image" href="https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6MzczNSwicHVyIjoiYmxvYl9pZCJ9fQ==--883f3fd4e1b571538035b5680c8d4a9eb504b1f6/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Source%20code-amico.png"/><link rel="preload" as="image" href="/vite/assets/development-BVihs_d5.png"/><div id="app" data-page="{"component":"web/qna/questions/show","props":{"errors":{},"locale":"ru","language":"ru","httpsHost":"https://ru.hexlet.io","host":"ru.hexlet.io","colorScheme":"light","auth":{"user":{"id":null,"last_viewed_notification_id":null,"email":null,"state":null,"first_name":"","last_name":"","created_at":"2026-02-26T20:44:01.609Z","current_program":null,"current_team":null,"full_name":"","guest":true,"can_use_paid_features":false,"is_hexlet_employee":false,"sanitized_phone_number":"","can_subscribe":true,"can_renew_education":false}},"cloudflareTurnstileSiteKey":"0x4AAAAAAA15KmeFXzd2H0Xo","vkIdClientId":"51586979","yandexIdClientId":"88d071f1d3384eb4bd1deb37910235c7","formAuthToken":"v3RhNE1WDcaJWbNX6IxGKBZeDXvUHnzpPJQtP_c9FrlQpaoDvyigpj8al8_kg7Zf1lcg0dwpgkuBdLdrpTrx1w","category":{"id":15,"title":"Глоссарий","slug":"glossary","questions_count":382,"locale":"ru"},"mainStackCategory":{"id":2,"name":"Курсы по веб-разработке","slug":"web_development","short_name":"Веб-разработка","order":190,"state":"published","category_slug":"courses_web_development"},"answerDto":{"id":null,"body":"","meta":{"model":"question_answer","relations":{}}},"question":{"creator":{"id":104929,"email":"feycot@gmail.com","first_name":"Nikolai","last_name":"Gagarinov","telegram":"","full_name":"Nikolai Gagarinov","removed":false},"category":{"id":15,"title":"Глоссарий","slug":"glossary","questions_count":382,"locale":"ru"},"tags":[],"id":3591,"answers_count":2,"slug":"chto-takoe-ascii","state":"published","title":"ASCII","created_at":"2023-06-05T10:02:19.282Z","details":null,"best_answer_id":5158,"related_stacks_count":5},"answers":[{"user":{"id":104929,"email":"feycot@gmail.com","first_name":"Nikolai","last_name":"Gagarinov","telegram":"","full_name":"Nikolai Gagarinov","removed":false},"question":{"creator":{"id":104929,"email":"feycot@gmail.com","first_name":"Nikolai","last_name":"Gagarinov","telegram":"","full_name":"Nikolai Gagarinov","removed":false},"category":{"id":15,"title":"Глоссарий","slug":"glossary","questions_count":382,"locale":"ru"},"tags":[],"id":3591,"answers_count":2,"slug":"chto-takoe-ascii","state":"published","title":"ASCII","created_at":"2023-06-05T10:02:19.282Z","details":null,"best_answer_id":5158,"related_stacks_count":5},"id":5158,"state":"active","body":"ASCII (American Standard Code for Information Interchange) — американский стандарт кодирования символов, разработанный для обмена текстовой информацией между устройствами и программами. В таблице определено 128 позиций (0-127), где каждой букве, цифре, знаку препинания или управляющей команде соответствует числовое значение.\n\nЭтот стандарт стал универсальной системой представления текста в цифровом виде и заложил фундамент для всех последующих кодировок, включая Unicode. Его принципы до сих пор применяются в операционных системах, языках программирования и сетевых протоколах.\n\n\n\nASCII описывает систему, где каждый символ представлен числовым кодом. Компьютеры оперируют не знаками, а числами, поэтому кодировка обеспечивает взаимопонимание между устройствами.\n\nПример числовых соответствий:\n\n* A — 65\n\n* a — 97\n\n* пробел — 32\n\n* 0 — 48\n\nБлагодаря единой таблице любой символ читается одинаково на разных платформах. Этот принцип стал ключевым для развития вычислительной техники и сетевых коммуникаций.\n\n## Краткая суть и значение в истории IT\n\nПоявление ASCII стало поворотным моментом в истории ИТ. До его утверждения каждый производитель применял собственные таблицы символов, из\\-за чего данные, переданные с одного устройства, могли отображаться некорректно на другом.\n\nASCII впервые установил единые правила, сделав возможным массовый обмен информацией между несовместимыми ранее системами. Этот шаг превратил текст в универсальную форму данных и стал основой для развития телекоммуникаций, программирования и компьютерных сетей.\n\n### История появления\n\nASCII возник не как случайное изобретение, а как необходимость — ответ на стремительное развитие телекоммуникаций и вычислительной техники середины XX века. Переход от аналоговой связи к цифровой требовал унифицированного языка, который понимали бы и машины, и операторы. Этот язык должен был быть простым, компактным и пригодным для любых устройств, от телетайпов до первых компьютеров.\n\n### Контекст 1960-х\n\nВ послевоенные годы активно использовались телетайпы — электромеханические машины, способные печатать сообщения, передаваемые по телефонным линиям. Они заменяли телеграф и использовались в армии, авиации, банках и редакциях газет. Каждая модель имела собственный набор кодов: Baudot, Murray, ITA2, позднее — внутренние таблицы производителей вроде Western Electric или Teletype Corporation.\n\nТакая разрозненность вызывала постоянные ошибки: одни и те же байты трактовались как разные символы, данные терялись или искажались.\n\nК началу 1960-х стало очевидно, что требуются единые стандарты передачи текстовой информации. К этому времени появлялись первые компьютеры, но обмен данными между ними был сложен именно из\\-за несовместимости кодировок. Кроме того, необходимо было задать не только буквы и цифры, но и управляющие команды, такие как возврат каретки, перевод строки или сигнал завершения передачи. Всё это подтолкнуло инженеров и производителей к созданию общего системного языка символов.\n\nАмериканская ассоциация стандартов (ASA) сформировала специальный комитет X3.4, куда вошли представители компаний IBM, AT\\&T, Honeywell и Bell Labs. Их задачей было определить набор символов, достаточный для любых коммуникаций, но при этом компактный, чтобы помещался в байт данных — восемь бит. Первые проекты включали больше 200 символов, однако для простоты систему сократили до 128\\.\n\n### Организация ANSI и принятие стандарта\n\nПосле нескольких лет обсуждений в 1963 году была опубликована первая спецификация ASCII. В документе определялись:\n\n* числовые коды для латинских букв, цифр и основных знаков препинания;\n\n* управляющие символы (NUL, LF, CR, ESC и другие);\n\n* структура таблицы — 7-битная, что обеспечивало совместимость с восьмибитными системами, где один бит использовался для контроля ошибок.\n\nВ 1967 году стандарт получил официальное утверждение от ANSI (American National Standards Institute), сменившего ASA. В 1968 году добавлены последние элементы — вертикальная черта «|» и тильда «\\~». Этот набор в дальнейшем практически не менялся и используется в неизменном виде до сих пор.\n\nПринятие ASCII совпало с формированием первых компьютерных сетей — ARPANET и коммерческих телекоммуникационных линий. Появился реальный инструмент для унификации обмена текстом между различными вычислительными системами, независимо от производителя и архитектуры.\n\nКроме того, ASCII стал частью международного стандарта ISO 646, что позволило адаптировать его для разных стран: в национальных версиях некоторые символы заменялись (например, знак доллара на фунт в британском варианте), но основа оставалась общей.\n\nASCII стал своего рода «латинским алфавитом» для машин — простым, понятным и универсальным языком коммуникации.\n\n### Распространение и применение\n\nПосле стандартизации ASCII быстро получил признание индустрии. Он стал основой для развития операционных систем и языков программирования.\n\nВ 1970-е годы кодировка внедряется в UNIX, язык C и большинство терминалов того времени. Команды, системные сообщения и текстовые интерфейсы опирались исключительно на ASCII.\n\nВскоре таблица ASCII стала обязательным элементом компьютерной архитектуры:\n\n* микропроцессоры Intel, DEC и Motorola изначально проектировались с учётом ASCII-кодировки;\n\n* принтеры и модемы использовали её при передаче текстовых данных;\n\n* протоколы связи (SMTP, FTP, HTTP) строились на текстовых командах, составленных из ASCII-символов.\n\nНапример, строки заголовков в письмах электронной почты или HTTP-запросах до сих пор передаются в виде обычного ASCII-текста, что гарантирует читаемость на любых устройствах.\n\n## Принципы кодирования в ASCII\n\nЛюбая система обработки данных опирается на способ представления информации в виде чисел. Для компьютера текст — это не набор букв, а совокупность бинарных значений, которые он может хранить, передавать и преобразовывать. Кодировка ASCII устанавливает строгие правила соответствия между символами и их числовыми кодами. Этот подход обеспечивает однозначность интерпретации данных и совместимость между различными устройствами и программами.\n\n### Почему символы кодируются числами\n\nЦифровые устройства оперируют двоичными значениями (0 и 1). Чтобы компьютер мог обрабатывать текст, символы должны быть представлены в числовом виде. Таблица ASCII задаёт соответствие между символом и его числом. Например, буква A соответствует двоичному коду 01000001\\.\n\n### Системы представления\n\nОдин и тот же символ можно выразить в трёх формах:\n\n* Двоичная: 01000001\n\n* Десятичная: 65\n\n* Шестнадцатеричная: 41\n\nДвоичный вид понятен машине, десятичный — человеку, а шестнадцатеричный удобен при отладке и анализе.\n\n### Управляющие и печатные символы\n\nПервые 32 кода (0–31) — управляющие. Они не имеют графического отображения и используются для сигналов «перевод строки», «звонок», «возврат каретки» и т. д.\n\nКоды 32–126 — печатные символы: буквы, цифры и знаки препинания. Код 127 — DEL, удаление символа.\n\nТакое разделение позволило описывать не только текст, но и процессы его вывода на экран или печать.\n\n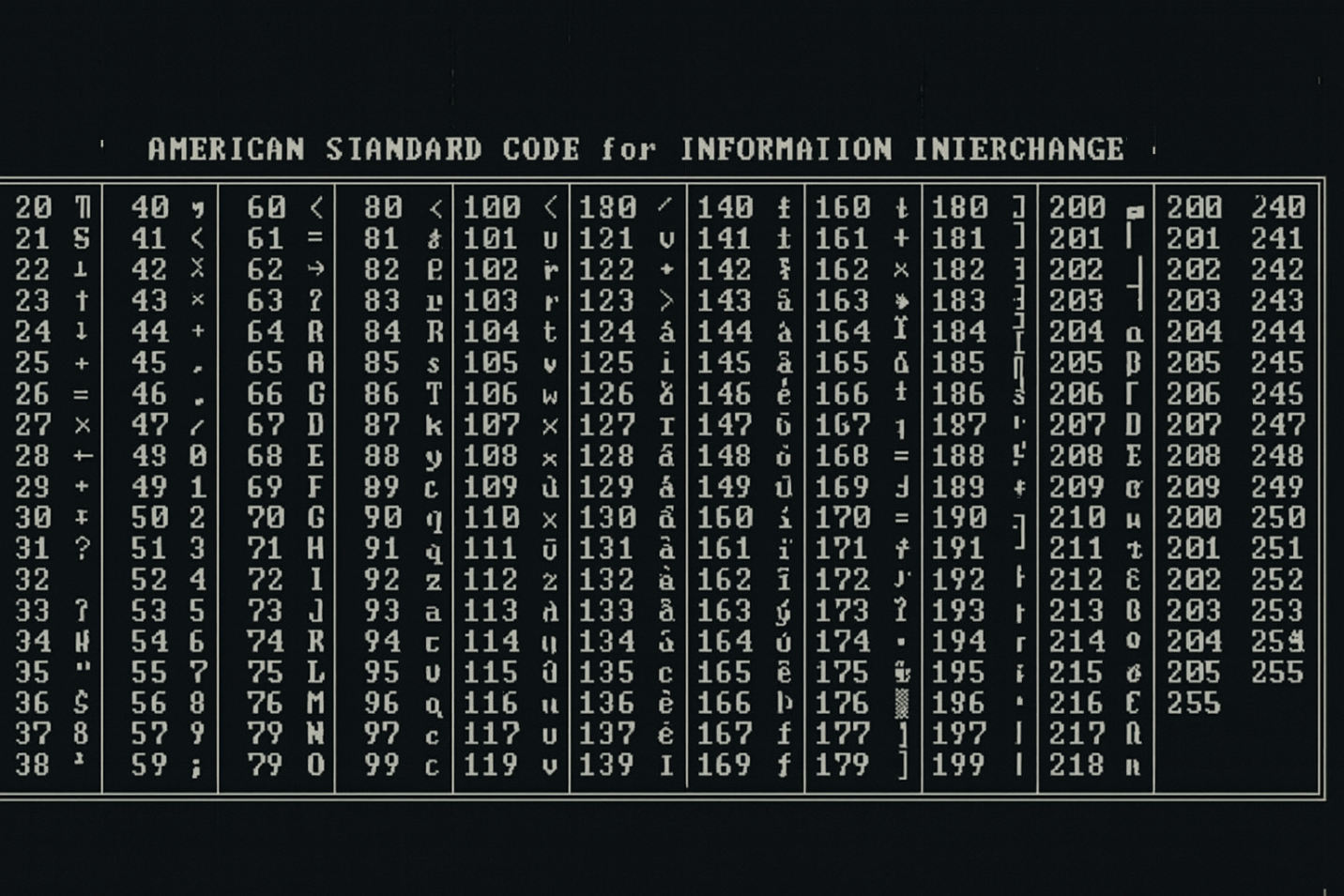\n\n## Структура таблицы ASCII\n\nТаблица ASCII построена таким образом, чтобы распределение кодов отражало функциональное значение символов. Порядок не случаен: управляющие коды идут первыми, за ними — пробел, цифры, буквы и специальные знаки. Такое расположение облегчает сортировку, поиск, редактирование и работу с текстом в программном обеспечении. Благодаря логичной структуре таблица остаётся удобной для анализа даже спустя десятилетия после создания.\n\n### Деление на диапазоны\n\n| Диапазон | Назначение |\n|:---------|:------------------------|\n| 0–31 | Управляющие команды |\n| 32 | Пробел |\n| 33–47 | Знаки препинания |\n| 48–57 | Цифры |\n| 58–64 | Дополнительные знаки |\n| 65–90 | Заглавные буквы |\n| 91–96 | Скобки и символы |\n| 97–122 | Строчные буквы |\n| 123–126 | Фигурные скобки, тильда |\n| 127 | Удаление |\n\n### Разница между регистрами\n\nЗаглавные и строчные буквы различаются на 32 единицы в десятичной системе. Это свойство используется в программах для преобразования регистра:\n\n```python\n# Python: разница в кодах\n\nord('a') - ord('A') # 32\n```\n\nТакое упорядочение упрощает сортировку и поиск по алфавиту.\n\n## Расширения ASCII\n\nСо временем базового диапазона ASCII стало недостаточно. Развитие международных вычислительных систем и увеличение числа языков, использующих нелатинские алфавиты, потребовали расширения набора символов. Стандарт из 128 позиций покрывал только английский язык и основные знаки препинания, что ограничивало его применимость в глобальной среде. При этом сохранялась необходимость совместимости со старыми системами, поэтому разработчики выбрали путь расширения таблицы, а не создания нового стандарта.\n\n### Extended ASCII\n\nБазовый диапазон 0–127 был дополнен новыми символами, образовав 8-битный набор 0–255. Расширенные версии получили общее название Extended ASCII. Они включали буквы с диакритикой, символы национальных алфавитов, графические и служебные элементы.\n\nНаиболее распространённые варианты:\n\n* ISO 8859-1 (Latin-1) — охватывает языки Западной Европы;\n\n* Windows-1252 — версия Microsoft с типографскими кавычками, знаком евро и дополнительными символами;\n\n* Mac Roman — использовалась в старых операционных системах Apple.\n\nКлючевым принципом расширенных кодировок стала обратная совместимость: первые 128 позиций полностью совпадали с оригинальной таблицей ASCII. Это гарантировало корректную работу старых программ при обработке новых текстов.\n\nОднако появление множества вариаций породило новую проблему — несовместимость между ними. Один и тот же байт в разных кодировках мог обозначать разные символы, что приводило к искажению текста при передаче между системами. Например, код 0x80 в Windows-1252 соответствует типографской кавычке, а в ISO 8859-1 не используется вовсе. Эта ситуация сделала невозможным создание единой международной текстовой среды.\n\n### Национальные варианты\n\nВ разных странах появились собственные расширения.\n\n* В СССР и России — KOI8-R и CP866, обеспечивавшие поддержку кириллицы;\n\n* В Восточной Европе — ISO 8859-2 для польского, чешского и венгерского языков;\n\n* В Азии — локальные кодировки для японского, китайского и корейского письма.\n\nНесмотря на адаптацию к национальным алфавитам, эти кодировки не были совместимы между собой. Один и тот же документ мог отображаться по-разному на разных устройствах, что усложняло международный обмен данными.\n\n### Ограничения\n\nРасширенные наборы отличались расположением символов и правилами интерпретации байтов. Один код мог обозначать разные буквы в разных системах, что делало невозможным универсальную обработку текстов. Эта проблема стала главным стимулом для перехода к универсальному стандарту Unicode, охватывающему все письменности мира и сохраняющему совместимость с ASCII в первых 128 кодах.\n\n## ASCII в программировании\n\nASCII — базовая кодировка для большинства языков программирования. Любой символ можно преобразовать в число и обратно:\n\n```python\nprint(ord('A')) # 65\nprint(chr(97)) # a\n```\n\nВ языке C:\n\n```c\n#include <stdio.h>\n\nint main() {\n printf(\"%d\\n\", 'A'); // 65\n printf(\"%c\\n\", 97); // a\n return 0;\n}\n```\n\nЭти функции используются при обработке строк, шифровании, анализе протоколов и разработке терминальных интерфейсов.\n\n### Escape-последовательности\n\nУправляющие символы в программировании записываются через обратный слэш:\n\n* `\\n` — перевод строки (LF, код 10);\n* `\\r` — возврат каретки (CR, код 13);\n* `\\t` — табуляция (TAB, код 9);\n* `\\b` — шаг назад (BS, код 8).\n\nЭти комбинации позволяют форматировать текст при выводе и управлять позиционированием курсора.\n\n## ASCII в практике\n\nНесмотря на появление Unicode и множества современных кодировок, ASCII продолжает использоваться в тысячах программных и аппаратных систем по всему миру. Его простота, минимальные требования к ресурсам и абсолютная совместимость делают стандарт идеальным для базового обмена текстовой информацией. ASCII остаётся неотъемлемой частью архитектуры сетевых протоколов, операционных систем, микроконтроллеров и конфигурационных файлов.\nВ большинстве случаев именно ASCII лежит в основе служебных структур данных, системных логов и коммуникаций между устройствами.\n\n### Применение в системах\n\n1. Текстовые файлы — базовые форматы .txt, .ini, .cfg, .log и конфигурационные документы используют только ASCII-символы, что обеспечивает их универсальное чтение в любой среде.\n\n2. Сетевые протоколы — команды, заголовки и ответы в HTTP, SMTP, FTP, POP3, IMAP оформляются в виде строк ASCII, что гарантирует читаемость и стабильность работы протоколов на разных платформах.\n\n3. Терминалы и консоли — интерфейсы UNIX, Linux и Windows CMD передают команды и результаты выполнения в ASCII-потоках, обеспечивая совместимость между оболочками и удалёнными серверами.\n\n4. Встраиваемые системы — микроконтроллеры, промышленные контроллеры и IoT-устройства хранят параметры и диагностические данные в текстовом ASCII-формате для упрощения отладки и взаимодействия с инженерным ПО.\n\n### ASCII art и креативные применения\n\nASCII применяется и за пределами программирования. Художники создают изображения, используя символы как пиксели. Примеры таких работ используются в логотипах, баннерах, ретро-играх и генераторах текста. Этот вид искусства сохраняет популярность благодаря минимализму и совместимости с любым терминалом.\n\n## ASCII и Unicode\n\nРазвитие компьютерных систем и рост глобальных коммуникаций потребовали кодировки, способной охватывать не только латиницу, но и все мировые письменности. К началу 1990-х годов стало очевидно, что набор ASCII, включающий всего 128 символов, не справляется с этой задачей. Возникла потребность в универсальном стандарте, объединяющем национальные алфавиты и технические символы, но при этом совместимом с уже существующими системами.\nТак появился Unicode — логическое продолжение ASCII, расширившее его принципы до глобального масштаба. Unicode стал основой современной цифровой коммуникации, сохранив при этом преемственность с оригинальным стандартом.\n\n### Отличия и совместимость\n\nUnicode — расширение идей ASCII. В нём предусмотрено более двух миллионов кодовых позиций, охватывающих все известные письменности, математические и технические знаки, пиктограммы и эмодзи. Первые 128 кодов полностью совпадают с таблицей ASCII, что обеспечивает полную обратную совместимость.\n\nКодировки UTF-8, UTF-16 и UTF-32 реализуют разные способы хранения символов Unicode в памяти и передаче данных. Наиболее распространённой стала UTF-8, так как она сохраняет однобайтовое представление для символов ASCII и использует больше байтов только при необходимости.\n\n### Почему Unicode не вытеснил ASCII\n\nНесмотря на универсальность Unicode, ASCII остаётся востребованным в областях, где важны простота, стабильность и минимальный размер данных.\n\nПреимущества ASCII:\n\n* минимальный размер символа — 1 байт;\n\n* высокая скорость обработки;\n\n* совместимость с устаревшими и встроенными протоколами;\n\n* устойчивость на всех платформах и в любых языках программирования.\n\nUnicode применяется для многоязычных систем, веб\\-приложений и документов, где требуется поддержка различных алфавитов. ASCII продолжает использоваться в базовых служебных структурах, системном программировании, логах, сетевых заголовках и текстовых протоколах, где производительность и надёжность важнее универсальности.\n\n## Таблица символов ASCII (0–127)\n\n| DEC | HEX | Символ | Назначение |\n|-------|-------|-------------------------------|--------------------------|\n| 0 | 0 | NUL | Null |\n| 1 | 1 | SOH | Start of Heading |\n| 2 | 2 | STX | Start of Text |\n| 3 | 3 | ETX | End of Text |\n| 4 | 4 | EOT | End of Transmission |\n| 5 | 5 | ENQ | Enquiry |\n| 6 | 6 | ACK | Acknowledge |\n| 7 | 7 | BEL | Звуковой сигнал |\n| 8 | 8 | BS | Backspace |\n| 9 | 9 | TAB | Горизонтальная табуляция |\n| 10 | 0A | LF | Перевод строки |\n| 11 | 0B | VT | Вертикальная табуляция |\n| 12 | 0C | FF | Прогон страницы |\n| 13 | 0D | CR | Возврат каретки |\n| 14 | 0E | SO | Shift Out |\n| 15 | 0F | SI | Shift In |\n| 16–31 | 10–1F | — | Управляющие коды |\n| 32 | 20 | (Space) | Пробел |\n| 33–47 | 21–2F | ! \" # $ % & ' ( ) * + , - . / | Знаки препинания |\n| 48–57 | 30–39 | 0–9 | Цифры |\n| 58–64 | 3A–40 | : ; < = > ? @ | Символы |\n| 65–90 | 41–5A | A–Z | Заглавные буквы |\n| 91–96 | 5B–60 | [ \\ ] ^ _ ` | Скобки и служебные |\n| 97–122 | 61–7A | a–z | Строчные буквы |\n| 123–126 | 7B–7E | { | } ~ |\n| 127 | 7F | DEL | Удаление |\n\n\nЭта таблица образует минимальный набор символов, поддерживаемый всеми системами без исключения.\n\n## Преимущества и ограничения ASCII\n\nПосле десятилетий использования ASCII остаётся одним из самых устойчивых стандартов в сфере информационных технологий. Его принципы просты, но именно эта простота обеспечила долговечность и совместимость с современными системами. При этом у стандарта есть объективные пределы, обусловленные историческими ограничениями его разработки. Рассмотрим сильные стороны и недостатки ASCII с позиции современного ИТ-контекста.\n\n### Преимущества\n\n* Простая структура и лёгкая реализация.\n\n* Полная совместимость между устройствами, операционными системами и протоколами.\n\n* Небольшой объём данных — каждый символ занимает 1 байт.\n\n* Надёжность и устойчивость при передаче информации в любых сетях.\n\n* Базовая совместимость с Unicode и его подмножествами (первые 128 кодов полностью совпадают).\n\nБлагодаря этим свойствам ASCII до сих пор используется как внутренний формат системных утилит, терминалов, микроконтроллеров и текстовых протоколов, где минимализм и предсказуемость критически важны.\n\n### Ограничения\n\n* Всего 128 символов — недостаточно для национальных алфавитов и расширенных наборов знаков.\n\n* Отсутствие поддержки диакритики, символов валют, графических элементов и специальных обозначений.\n\n* Невозможность прямого применения в многоязычных и контентных системах.\n\n* Проблемы совместимости при переходе на расширенные версии и другие локальные кодировки.\n\nНесмотря на это, ASCII остаётся основой большинства современных текстовых форматов. Такие технологии, как HTML, XML, JSON, CSV, используют ASCII в качестве базового слоя представления данных, а Unicode — лишь как надстройку для дополнительных символов. Это доказывает, что даже в эпоху глобальных стандартов минимализм ASCII продолжает обеспечивать стабильность цифрового обмена.\n","votes_up_count":1,"votes_down_count":0,"created_at":"2025-11-18T15:01:56.210Z","user_id":104929,"category_slug":"glossary"},{"user":{"id":647057,"email":"redkinaelena10.02.89@yandex.ru","first_name":"Елена","last_name":"Редькина","telegram":"89670235676","full_name":"Елена Редькина","removed":false},"question":{"creator":{"id":104929,"email":"feycot@gmail.com","first_name":"Nikolai","last_name":"Gagarinov","telegram":"","full_name":"Nikolai Gagarinov","removed":false},"category":{"id":15,"title":"Глоссарий","slug":"glossary","questions_count":382,"locale":"ru"},"tags":[],"id":3591,"answers_count":2,"slug":"chto-takoe-ascii","state":"published","title":"ASCII","created_at":"2023-06-05T10:02:19.282Z","details":null,"best_answer_id":5158,"related_stacks_count":5},"id":3301,"state":"active","body":"ASCII (American Standard Code for Information Interchange) - это таблица символов, которая используется для представления букв, цифр и других символов в виде чисел. ASCII используется в большинстве компьютерных систем и является основой для других кодировок, таких как UTF-8 и UTF-16.","votes_up_count":0,"votes_down_count":0,"created_at":"2023-11-16T20:24:20.362Z","user_id":647057,"category_slug":"glossary"}],"relatedQuestions":[{"creator":{"id":583099,"email":"shade.mailbox@gmail.com","first_name":"Arthur","last_name":"Cheremisin","telegram":"","full_name":"Arthur Cheremisin","removed":false},"category":{"id":15,"title":"Глоссарий","slug":"glossary","questions_count":382,"locale":"ru"},"tags":[{"id":1095,"slug":"data-analitika","name":"data-аналитика"},{"id":1096,"slug":"analitika","name":"Аналитика"}],"id":2709,"answers_count":2,"slug":"chto-takoe-pandas","state":"published","title":"Pandas","created_at":"2023-03-29T12:39:32.428Z","details":"","best_answer_id":5306,"related_stacks_count":5},{"creator":{"id":104929,"email":"feycot@gmail.com","first_name":"Nikolai","last_name":"Gagarinov","telegram":"","full_name":"Nikolai Gagarinov","removed":false},"category":{"id":15,"title":"Глоссарий","slug":"glossary","questions_count":382,"locale":"ru"},"tags":[],"id":3577,"answers_count":1,"slug":"chto-takoe-1c-buhgalteriya","state":"published","title":"1C:Бухгалтерия","created_at":"2023-06-05T10:02:18.923Z","details":null,"best_answer_id":3315,"related_stacks_count":0},{"creator":{"id":104929,"email":"feycot@gmail.com","first_name":"Nikolai","last_name":"Gagarinov","telegram":"","full_name":"Nikolai Gagarinov","removed":false},"category":{"id":15,"title":"Глоссарий","slug":"glossary","questions_count":382,"locale":"ru"},"tags":[],"id":3578,"answers_count":1,"slug":"chto-takoe-1c-predpriyatie","state":"published","title":"1C:Предприятие","created_at":"2023-06-05T10:02:18.960Z","details":null,"best_answer_id":3314,"related_stacks_count":5},{"creator":{"id":104929,"email":"feycot@gmail.com","first_name":"Nikolai","last_name":"Gagarinov","telegram":"","full_name":"Nikolai Gagarinov","removed":false},"category":{"id":15,"title":"Глоссарий","slug":"glossary","questions_count":382,"locale":"ru"},"tags":[],"id":3579,"answers_count":1,"slug":"chto-takoe-a-b-testirovanie","state":"published","title":"A/B-тестирование","created_at":"2023-06-05T10:02:18.988Z","details":null,"best_answer_id":3313,"related_stacks_count":5},{"creator":{"id":104929,"email":"feycot@gmail.com","first_name":"Nikolai","last_name":"Gagarinov","telegram":"","full_name":"Nikolai Gagarinov","removed":false},"category":{"id":15,"title":"Глоссарий","slug":"glossary","questions_count":382,"locale":"ru"},"tags":[],"id":3580,"answers_count":1,"slug":"chto-takoe-agile","state":"published","title":"Agile","created_at":"2023-06-05T10:02:19.016Z","details":null,"best_answer_id":3312,"related_stacks_count":5}],"relatedLandings":[{"stack":{"id":34,"slug":"algorithms","title":"Алгоритмы и структуры данных","audience":"for_programmers","start_type":"anytime","pricing_model":"subscription","priority":"medium","kind":"track","state":"published","stack_state":"finished","order":4000,"duration_in_months":2},"id":56,"slug":"algorithms","title":"Алгоритмы и структуры данных","subtitle":"Навык, который увеличит ваши шансы пройти алгоритмическое интервью в международные компании на 80%","subtitle_for_lists":"Алгоритмы для собеседований","locale":"ru","current":true,"duration_in_months_text":"2 месяца","stack_slug":"algorithms","price_text":"от 3 900 ₽","duration_text":"2 месяца","cover_list_variant":"https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6NDAyOCwicHVyIjoiYmxvYl9pZCJ9fQ==--ae9eed98663dd1201759d042a5ba7ca790866156/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Programming-bro.png"},{"stack":{"id":50,"slug":"discrete-mathematics","title":"Дискретная математика","audience":"for_beginners","start_type":"anytime","pricing_model":"subscription","priority":"medium","kind":"track","state":"published","stack_state":"finished","order":4650,"duration_in_months":1},"id":88,"slug":"discrete-mathematics","title":"Дискретная математика","subtitle":"Навык дискретной математики для укрепления теоретических знаний и лучшего понимания алгоритмов и структур данных","subtitle_for_lists":"Дискретная математика для программистов","locale":"ru","current":true,"duration_in_months_text":"1 месяц","stack_slug":"discrete-mathematics","price_text":"от 3 900 ₽","duration_text":"1 месяц","cover_list_variant":"https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6MzY2MSwicHVyIjoiYmxvYl9pZCJ9fQ==--e9c2b6bde361adaac625a7f47d8b9671c17f3ddb/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Mathematics-bro.png"},{"stack":{"id":12,"slug":"frontend","title":"Фронтенд-разработчик","audience":"for_beginners","start_type":"weekly","pricing_model":"purchase","priority":"high","kind":"profession","state":"published","stack_state":"finished","order":20,"duration_in_months":10},"id":17,"slug":"frontend","title":"Фронтенд-разработчик","subtitle":"Изучите HTML, CSS, JavaScript и React","subtitle_for_lists":"Изучите HTML, CSS, JavaScript и React","locale":"ru","current":true,"duration_in_months_text":"10 месяцев","stack_slug":"frontend","price_text":"от 6 792 ₽","duration_text":"10 месяцев","cover_list_variant":"https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6MzcyNywicHVyIjoiYmxvYl9pZCJ9fQ==--2d5cbbf5c3b4a73ae4b2c50632305d78f5872e4d/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Programmer-rafiki.png"},{"stack":{"id":19,"slug":"layout-designer","title":"Профессиональная верстка","audience":"for_beginners","start_type":"anytime","pricing_model":"purchase","priority":"medium","kind":"track","state":"published","stack_state":"finished","order":1700,"duration_in_months":5},"id":26,"slug":"professional-layout","title":"Профессиональная верстка","subtitle":"Навык адаптивной вёрстки с современными подходами для корректного отображения сайтов на любых устройствах и разрешениях","subtitle_for_lists":"Адаптивная вёрстка для отображения на любых устройствах ","locale":"ru","current":true,"duration_in_months_text":"5 месяцев","stack_slug":"layout-designer","price_text":"от 3 900 ₽","duration_text":"5 месяцев","cover_list_variant":"https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6NDAzNCwicHVyIjoiYmxvYl9pZCJ9fQ==--ba516ea9573bdfcd1d21e2aa0fff8818561828f2/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Typing-bro.png"},{"stack":{"id":3,"slug":"java","title":"Java-разработчик","audience":"for_beginners","start_type":"weekly","pricing_model":"purchase","priority":"high","kind":"profession","state":"published","stack_state":"finished","order":30,"duration_in_months":10},"id":3,"slug":"java","title":"Java-разработчик","subtitle":"Изучите Java и фреймворк Spring Boot и REST API","subtitle_for_lists":"Изучите Java и фреймворк Spring Boot и REST API","locale":"ru","current":true,"duration_in_months_text":"10 месяцев","stack_slug":"java","price_text":"от 6 792 ₽","duration_text":"10 месяцев","cover_list_variant":"https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6MzczNSwicHVyIjoiYmxvYl9pZCJ9fQ==--883f3fd4e1b571538035b5680c8d4a9eb504b1f6/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Source%20code-amico.png"}]},"url":"/qna/glossary/questions/chto-takoe-ascii","version":"8f286f6358a90a7bef2263b3a6edf5a90a94fa42","encryptHistory":false,"clearHistory":false}"><style data-mantine-styles="true">:root, :host{--mantine-font-family: Arial, sans-serif;--mantine-font-family-headings: Arial, sans-serif;--mantine-heading-font-weight: normal;--mantine-radius-default: 0rem;--mantine-primary-color-filled: var(--mantine-color-indigo-filled);--mantine-primary-color-filled-hover: var(--mantine-color-indigo-filled-hover);--mantine-primary-color-light: var(--mantine-color-indigo-light);--mantine-primary-color-light-hover: var(--mantine-color-indigo-light-hover);--mantine-primary-color-light-color: var(--mantine-color-indigo-light-color);--mantine-spacing-xxl: calc(4rem * var(--mantine-scale));--mantine-font-size-xs: 12px;--mantine-font-size-sm: 14px;--mantine-font-size-md: 16px;--mantine-font-size-lg: clamp(16.0000px, calc(15.2727px + 0.2273vw), 18.0000px);--mantine-font-size-xl: clamp(16.0000px, calc(14.5455px + 0.4545vw), 20.0000px);--mantine-font-size-display-3: clamp(32.0000px, calc(26.1818px + 1.8182vw), 48.0000px);--mantine-font-size-display-2: clamp(36.0000px, calc(25.8182px + 3.1818vw), 64.0000px);--mantine-font-size-display-1: clamp(40.0000px, calc(25.4545px + 4.5455vw), 80.0000px);--mantine-font-size-h1: clamp(28.0000px, calc(23.6364px + 1.3636vw), 40.0000px);--mantine-font-size-h2: clamp(24.0000px, calc(21.0909px + 0.9091vw), 32.0000px);--mantine-font-size-h3: clamp(20.0000px, calc(17.0909px + 0.9091vw), 28.0000px);--mantine-font-size-h4: clamp(16.0000px, calc(13.0909px + 0.9091vw), 24.0000px);--mantine-font-size-h5: clamp(16.0000px, calc(14.5455px + 0.4545vw), 20.0000px);--mantine-font-size-h6: 1rem;--mantine-primary-color-0: var(--mantine-color-indigo-0);--mantine-primary-color-1: var(--mantine-color-indigo-1);--mantine-primary-color-2: var(--mantine-color-indigo-2);--mantine-primary-color-3: var(--mantine-color-indigo-3);--mantine-primary-color-4: var(--mantine-color-indigo-4);--mantine-primary-color-5: var(--mantine-color-indigo-5);--mantine-primary-color-6: var(--mantine-color-indigo-6);--mantine-primary-color-7: var(--mantine-color-indigo-7);--mantine-primary-color-8: var(--mantine-color-indigo-8);--mantine-primary-color-9: var(--mantine-color-indigo-9);--mantine-color-red-0: #ffeaea;--mantine-color-red-1: #fed4d4;--mantine-color-red-2: #f4a7a8;--mantine-color-red-3: #ec7878;--mantine-color-red-4: #e55050;--mantine-color-red-5: #e03131;--mantine-color-red-6: #e02829;--mantine-color-red-7: #c71a1c;--mantine-color-red-8: #b21218;--mantine-color-red-9: #9c0411;--mantine-color-violet-0: #fce9ff;--mantine-color-violet-1: #f1cfff;--mantine-color-violet-2: #e09bff;--mantine-color-violet-3: #d16fff;--mantine-color-violet-4: #be37fe;--mantine-color-violet-5: #b51afe;--mantine-color-violet-6: #b009ff;--mantine-color-violet-7: #9b00e4;--mantine-color-violet-8: #8a00cc;--mantine-color-violet-9: #7800b3;--mantine-color-indigo-0: #edecff;--mantine-color-indigo-1: #d6d5fe;--mantine-color-indigo-2: #aaa9f4;--mantine-color-indigo-3: #7b79eb;--mantine-color-indigo-4: #5451e4;--mantine-color-indigo-5: #3b37e0;--mantine-color-indigo-6: #2d2adf;--mantine-color-indigo-7: #1f1ec7;--mantine-color-indigo-8: #1819b2;--mantine-color-indigo-9: #0c149e;--mantine-color-cyan-0: #dffdff;--mantine-color-cyan-1: #caf5ff;--mantine-color-cyan-2: #99e8ff;--mantine-color-cyan-3: #64daff;--mantine-color-cyan-4: #3ccffe;--mantine-color-cyan-5: #24c8fe;--mantine-color-cyan-6: #00c2ff;--mantine-color-cyan-7: #00ade4;--mantine-color-cyan-8: #009acd;--mantine-color-cyan-9: #0085b5;--mantine-color-green-0: #e9fdec;--mantine-color-green-1: #d7f6dc;--mantine-color-green-2: #b0eab9;--mantine-color-green-3: #86df94;--mantine-color-green-4: #62d574;--mantine-color-green-5: #4ccf5f;--mantine-color-green-6: #3fcc54;--mantine-color-green-7: #2fb344;--mantine-color-green-8: #25a03b;--mantine-color-green-9: #138a2e;--mantine-color-yellow-0: #fff7e2;--mantine-color-yellow-1: #ffeecd;--mantine-color-yellow-2: #ffdc9c;--mantine-color-yellow-3: #ffc966;--mantine-color-yellow-4: #feb93a;--mantine-color-yellow-5: #feae1e;--mantine-color-yellow-6: #ffa90f;--mantine-color-yellow-8: #ca8200;--mantine-color-yellow-9: #af7000;--mantine-h1-font-size: clamp(28.0000px, calc(23.6364px + 1.3636vw), 40.0000px);--mantine-h1-font-weight: normal;--mantine-h2-font-size: clamp(24.0000px, calc(21.0909px + 0.9091vw), 32.0000px);--mantine-h2-font-weight: normal;--mantine-h3-font-size: clamp(20.0000px, calc(17.0909px + 0.9091vw), 28.0000px);--mantine-h3-font-weight: normal;--mantine-h4-font-size: clamp(16.0000px, calc(13.0909px + 0.9091vw), 24.0000px);--mantine-h4-font-weight: normal;--mantine-h5-font-size: clamp(16.0000px, calc(14.5455px + 0.4545vw), 20.0000px);--mantine-h5-font-weight: normal;--mantine-h6-font-size: 1rem;--mantine-h6-font-weight: normal;}
:root[data-mantine-color-scheme="dark"], :host([data-mantine-color-scheme="dark"]){--mantine-color-anchor: var(--mantine-color-text);--mantine-color-dimmed: #495057;--mantine-color-dark-filled: var(--mantine-color-dark-5);--mantine-color-dark-filled-hover: var(--mantine-color-dark-6);--mantine-color-dark-light: rgba(105, 105, 105, 0.15);--mantine-color-dark-light-hover: rgba(105, 105, 105, 0.2);--mantine-color-dark-light-color: var(--mantine-color-dark-0);--mantine-color-dark-outline: var(--mantine-color-dark-1);--mantine-color-dark-outline-hover: rgba(184, 184, 184, 0.05);--mantine-color-gray-filled: var(--mantine-color-gray-5);--mantine-color-gray-filled-hover: var(--mantine-color-gray-6);--mantine-color-gray-light: rgba(222, 226, 230, 0.15);--mantine-color-gray-light-hover: rgba(222, 226, 230, 0.2);--mantine-color-gray-light-color: var(--mantine-color-gray-0);--mantine-color-gray-outline: var(--mantine-color-gray-1);--mantine-color-gray-outline-hover: rgba(241, 243, 245, 0.05);--mantine-color-red-filled: var(--mantine-color-red-5);--mantine-color-red-filled-hover: var(--mantine-color-red-6);--mantine-color-red-light: rgba(236, 120, 120, 0.15);--mantine-color-red-light-hover: rgba(236, 120, 120, 0.2);--mantine-color-red-light-color: var(--mantine-color-red-0);--mantine-color-red-outline: var(--mantine-color-red-1);--mantine-color-red-outline-hover: rgba(254, 212, 212, 0.05);--mantine-color-pink-filled: var(--mantine-color-pink-5);--mantine-color-pink-filled-hover: var(--mantine-color-pink-6);--mantine-color-pink-light: rgba(250, 162, 193, 0.15);--mantine-color-pink-light-hover: rgba(250, 162, 193, 0.2);--mantine-color-pink-light-color: var(--mantine-color-pink-0);--mantine-color-pink-outline: var(--mantine-color-pink-1);--mantine-color-pink-outline-hover: rgba(255, 222, 235, 0.05);--mantine-color-grape-filled: var(--mantine-color-grape-5);--mantine-color-grape-filled-hover: var(--mantine-color-grape-6);--mantine-color-grape-light: rgba(229, 153, 247, 0.15);--mantine-color-grape-light-hover: rgba(229, 153, 247, 0.2);--mantine-color-grape-light-color: var(--mantine-color-grape-0);--mantine-color-grape-outline: var(--mantine-color-grape-1);--mantine-color-grape-outline-hover: rgba(243, 217, 250, 0.05);--mantine-color-violet-filled: var(--mantine-color-violet-5);--mantine-color-violet-filled-hover: var(--mantine-color-violet-6);--mantine-color-violet-light: rgba(209, 111, 255, 0.15);--mantine-color-violet-light-hover: rgba(209, 111, 255, 0.2);--mantine-color-violet-light-color: var(--mantine-color-violet-0);--mantine-color-violet-outline: var(--mantine-color-violet-1);--mantine-color-violet-outline-hover: rgba(241, 207, 255, 0.05);--mantine-color-indigo-filled: var(--mantine-color-indigo-5);--mantine-color-indigo-filled-hover: var(--mantine-color-indigo-6);--mantine-color-indigo-light: rgba(123, 121, 235, 0.15);--mantine-color-indigo-light-hover: rgba(123, 121, 235, 0.2);--mantine-color-indigo-light-color: var(--mantine-color-indigo-0);--mantine-color-indigo-outline: var(--mantine-color-indigo-1);--mantine-color-indigo-outline-hover: rgba(214, 213, 254, 0.05);--mantine-color-blue-filled: var(--mantine-color-blue-5);--mantine-color-blue-filled-hover: var(--mantine-color-blue-6);--mantine-color-blue-light: rgba(116, 192, 252, 0.15);--mantine-color-blue-light-hover: rgba(116, 192, 252, 0.2);--mantine-color-blue-light-color: var(--mantine-color-blue-0);--mantine-color-blue-outline: var(--mantine-color-blue-1);--mantine-color-blue-outline-hover: rgba(208, 235, 255, 0.05);--mantine-color-cyan-filled: var(--mantine-color-cyan-5);--mantine-color-cyan-filled-hover: var(--mantine-color-cyan-6);--mantine-color-cyan-light: rgba(100, 218, 255, 0.15);--mantine-color-cyan-light-hover: rgba(100, 218, 255, 0.2);--mantine-color-cyan-light-color: var(--mantine-color-cyan-0);--mantine-color-cyan-outline: var(--mantine-color-cyan-1);--mantine-color-cyan-outline-hover: rgba(202, 245, 255, 0.05);--mantine-color-teal-filled: var(--mantine-color-teal-5);--mantine-color-teal-filled-hover: var(--mantine-color-teal-6);--mantine-color-teal-light: rgba(99, 230, 190, 0.15);--mantine-color-teal-light-hover: rgba(99, 230, 190, 0.2);--mantine-color-teal-light-color: var(--mantine-color-teal-0);--mantine-color-teal-outline: var(--mantine-color-teal-1);--mantine-color-teal-outline-hover: rgba(195, 250, 232, 0.05);--mantine-color-green-filled: var(--mantine-color-green-5);--mantine-color-green-filled-hover: var(--mantine-color-green-6);--mantine-color-green-light: rgba(134, 223, 148, 0.15);--mantine-color-green-light-hover: rgba(134, 223, 148, 0.2);--mantine-color-green-light-color: var(--mantine-color-green-0);--mantine-color-green-outline: var(--mantine-color-green-1);--mantine-color-green-outline-hover: rgba(215, 246, 220, 0.05);--mantine-color-lime-filled: var(--mantine-color-lime-5);--mantine-color-lime-filled-hover: var(--mantine-color-lime-6);--mantine-color-lime-light: rgba(192, 235, 117, 0.15);--mantine-color-lime-light-hover: rgba(192, 235, 117, 0.2);--mantine-color-lime-light-color: var(--mantine-color-lime-0);--mantine-color-lime-outline: var(--mantine-color-lime-1);--mantine-color-lime-outline-hover: rgba(233, 250, 200, 0.05);--mantine-color-yellow-filled: var(--mantine-color-yellow-5);--mantine-color-yellow-filled-hover: var(--mantine-color-yellow-6);--mantine-color-yellow-light: rgba(255, 201, 102, 0.15);--mantine-color-yellow-light-hover: rgba(255, 201, 102, 0.2);--mantine-color-yellow-light-color: var(--mantine-color-yellow-0);--mantine-color-yellow-outline: var(--mantine-color-yellow-1);--mantine-color-yellow-outline-hover: rgba(255, 238, 205, 0.05);--mantine-color-orange-filled: var(--mantine-color-orange-5);--mantine-color-orange-filled-hover: var(--mantine-color-orange-6);--mantine-color-orange-light: rgba(255, 192, 120, 0.15);--mantine-color-orange-light-hover: rgba(255, 192, 120, 0.2);--mantine-color-orange-light-color: var(--mantine-color-orange-0);--mantine-color-orange-outline: var(--mantine-color-orange-1);--mantine-color-orange-outline-hover: rgba(255, 232, 204, 0.05);--app-cta-gradient: linear-gradient(90deg, var(--mantine-color-blue-9) 0%, var(--mantine-color-cyan-7) 100%);--app-color-surface: #2e2e2e;}
:root[data-mantine-color-scheme="light"], :host([data-mantine-color-scheme="light"]){--mantine-color-anchor: var(--mantine-color-text);--mantine-color-dimmed: #495057;--mantine-color-red-light: rgba(224, 40, 41, 0.1);--mantine-color-red-light-hover: rgba(224, 40, 41, 0.12);--mantine-color-red-outline-hover: rgba(224, 40, 41, 0.05);--mantine-color-violet-light: rgba(176, 9, 255, 0.1);--mantine-color-violet-light-hover: rgba(176, 9, 255, 0.12);--mantine-color-violet-outline-hover: rgba(176, 9, 255, 0.05);--mantine-color-indigo-light: rgba(45, 42, 223, 0.1);--mantine-color-indigo-light-hover: rgba(45, 42, 223, 0.12);--mantine-color-indigo-outline-hover: rgba(45, 42, 223, 0.05);--mantine-color-cyan-light: rgba(0, 194, 255, 0.1);--mantine-color-cyan-light-hover: rgba(0, 194, 255, 0.12);--mantine-color-cyan-outline-hover: rgba(0, 194, 255, 0.05);--mantine-color-green-light: rgba(63, 204, 84, 0.1);--mantine-color-green-light-hover: rgba(63, 204, 84, 0.12);--mantine-color-green-outline-hover: rgba(63, 204, 84, 0.05);--mantine-color-yellow-light: rgba(255, 169, 15, 0.1);--mantine-color-yellow-light-hover: rgba(255, 169, 15, 0.12);--mantine-color-yellow-outline-hover: rgba(255, 169, 15, 0.05);--app-color-surface: #f1f3f5;--app-cta-gradient: linear-gradient(90deg, var(--mantine-color-blue-filled) 0%, var(--mantine-color-cyan-5) 100%);}</style><style data-mantine-styles="classes">@media (max-width: 35.99375em) {.mantine-visible-from-xs {display: none !important;}}@media (min-width: 36em) {.mantine-hidden-from-xs {display: none !important;}}@media (max-width: 47.99375em) {.mantine-visible-from-sm {display: none !important;}}@media (min-width: 48em) {.mantine-hidden-from-sm {display: none !important;}}@media (max-width: 61.99375em) {.mantine-visible-from-md {display: none !important;}}@media (min-width: 62em) {.mantine-hidden-from-md {display: none !important;}}@media (max-width: 74.99375em) {.mantine-visible-from-lg {display: none !important;}}@media (min-width: 75em) {.mantine-hidden-from-lg {display: none !important;}}@media (max-width: 87.99375em) {.mantine-visible-from-xl {display: none !important;}}@media (min-width: 88em) {.mantine-hidden-from-xl {display: none !important;}}</style><script type="application/ld+json">{"@context":"https://schema.org","@type":"QAPage","mainEntity":{"@type":"Question","name":"ASCII","answerCount":2,"datePublished":"2023-06-05T10:02:19.282Z","author":{"@type":"Person","name":"Nikolai Gagarinov"},"acceptedAnswer":{"@type":"Answer","text":"ASCII (American Standard Code for Information Interchange) — американский стандарт кодирования символов, разработанный для обмена текстовой информацией между устройствами и программами. В таблице определено 128 позиций (0-127), где каждой букве, цифре, знаку препинания или управляющей команде соответствует числовое значение.\n\nЭтот стандарт стал универсальной системой представления текста в цифровом виде и заложил фундамент для всех последующих кодировок, включая Unicode. Его принципы до сих пор применяются в операционных системах, языках программирования и сетевых протоколах.\n\n\n\nASCII описывает систему, где каждый символ представлен числовым кодом. Компьютеры оперируют не знаками, а числами, поэтому кодировка обеспечивает взаимопонимание между устройствами.\n\nПример числовых соответствий:\n\n* A — 65\n\n* a — 97\n\n* пробел — 32\n\n* 0 — 48\n\nБлагодаря единой таблице любой символ читается одинаково на разных платформах. Этот принцип стал ключевым для развития вычислительной техники и сетевых коммуникаций.\n\n## Краткая суть и значение в истории IT\n\nПоявление ASCII стало поворотным моментом в истории ИТ. До его утверждения каждый производитель применял собственные таблицы символов, из\\-за чего данные, переданные с одного устройства, могли отображаться некорректно на другом.\n\nASCII впервые установил единые правила, сделав возможным массовый обмен информацией между несовместимыми ранее системами. Этот шаг превратил текст в универсальную форму данных и стал основой для развития телекоммуникаций, программирования и компьютерных сетей.\n\n### История появления\n\nASCII возник не как случайное изобретение, а как необходимость — ответ на стремительное развитие телекоммуникаций и вычислительной техники середины XX века. Переход от аналоговой связи к цифровой требовал унифицированного языка, который понимали бы и машины, и операторы. Этот язык должен был быть простым, компактным и пригодным для любых устройств, от телетайпов до первых компьютеров.\n\n### Контекст 1960-х\n\nВ послевоенные годы активно использовались телетайпы — электромеханические машины, способные печатать сообщения, передаваемые по телефонным линиям. Они заменяли телеграф и использовались в армии, авиации, банках и редакциях газет. Каждая модель имела собственный набор кодов: Baudot, Murray, ITA2, позднее — внутренние таблицы производителей вроде Western Electric или Teletype Corporation.\n\nТакая разрозненность вызывала постоянные ошибки: одни и те же байты трактовались как разные символы, данные терялись или искажались.\n\nК началу 1960-х стало очевидно, что требуются единые стандарты передачи текстовой информации. К этому времени появлялись первые компьютеры, но обмен данными между ними был сложен именно из\\-за несовместимости кодировок. Кроме того, необходимо было задать не только буквы и цифры, но и управляющие команды, такие как возврат каретки, перевод строки или сигнал завершения передачи. Всё это подтолкнуло инженеров и производителей к созданию общего системного языка символов.\n\nАмериканская ассоциация стандартов (ASA) сформировала специальный комитет X3.4, куда вошли представители компаний IBM, AT\\&T, Honeywell и Bell Labs. Их задачей было определить набор символов, достаточный для любых коммуникаций, но при этом компактный, чтобы помещался в байт данных — восемь бит. Первые проекты включали больше 200 символов, однако для простоты систему сократили до 128\\.\n\n### Организация ANSI и принятие стандарта\n\nПосле нескольких лет обсуждений в 1963 году была опубликована первая спецификация ASCII. В документе определялись:\n\n* числовые коды для латинских букв, цифр и основных знаков препинания;\n\n* управляющие символы (NUL, LF, CR, ESC и другие);\n\n* структура таблицы — 7-битная, что обеспечивало совместимость с восьмибитными системами, где один бит использовался для контроля ошибок.\n\nВ 1967 году стандарт получил официальное утверждение от ANSI (American National Standards Institute), сменившего ASA. В 1968 году добавлены последние элементы — вертикальная черта «|» и тильда «\\~». Этот набор в дальнейшем практически не менялся и используется в неизменном виде до сих пор.\n\nПринятие ASCII совпало с формированием первых компьютерных сетей — ARPANET и коммерческих телекоммуникационных линий. Появился реальный инструмент для унификации обмена текстом между различными вычислительными системами, независимо от производителя и архитектуры.\n\nКроме того, ASCII стал частью международного стандарта ISO 646, что позволило адаптировать его для разных стран: в национальных версиях некоторые символы заменялись (например, знак доллара на фунт в британском варианте), но основа оставалась общей.\n\nASCII стал своего рода «латинским алфавитом» для машин — простым, понятным и универсальным языком коммуникации.\n\n### Распространение и применение\n\nПосле стандартизации ASCII быстро получил признание индустрии. Он стал основой для развития операционных систем и языков программирования.\n\nВ 1970-е годы кодировка внедряется в UNIX, язык C и большинство терминалов того времени. Команды, системные сообщения и текстовые интерфейсы опирались исключительно на ASCII.\n\nВскоре таблица ASCII стала обязательным элементом компьютерной архитектуры:\n\n* микропроцессоры Intel, DEC и Motorola изначально проектировались с учётом ASCII-кодировки;\n\n* принтеры и модемы использовали её при передаче текстовых данных;\n\n* протоколы связи (SMTP, FTP, HTTP) строились на текстовых командах, составленных из ASCII-символов.\n\nНапример, строки заголовков в письмах электронной почты или HTTP-запросах до сих пор передаются в виде обычного ASCII-текста, что гарантирует читаемость на любых устройствах.\n\n## Принципы кодирования в ASCII\n\nЛюбая система обработки данных опирается на способ представления информации в виде чисел. Для компьютера текст — это не набор букв, а совокупность бинарных значений, которые он может хранить, передавать и преобразовывать. Кодировка ASCII устанавливает строгие правила соответствия между символами и их числовыми кодами. Этот подход обеспечивает однозначность интерпретации данных и совместимость между различными устройствами и программами.\n\n### Почему символы кодируются числами\n\nЦифровые устройства оперируют двоичными значениями (0 и 1). Чтобы компьютер мог обрабатывать текст, символы должны быть представлены в числовом виде. Таблица ASCII задаёт соответствие между символом и его числом. Например, буква A соответствует двоичному коду 01000001\\.\n\n### Системы представления\n\nОдин и тот же символ можно выразить в трёх формах:\n\n* Двоичная: 01000001\n\n* Десятичная: 65\n\n* Шестнадцатеричная: 41\n\nДвоичный вид понятен машине, десятичный — человеку, а шестнадцатеричный удобен при отладке и анализе.\n\n### Управляющие и печатные символы\n\nПервые 32 кода (0–31) — управляющие. Они не имеют графического отображения и используются для сигналов «перевод строки», «звонок», «возврат каретки» и т. д.\n\nКоды 32–126 — печатные символы: буквы, цифры и знаки препинания. Код 127 — DEL, удаление символа.\n\nТакое разделение позволило описывать не только текст, но и процессы его вывода на экран или печать.\n\n\n\n## Структура таблицы ASCII\n\nТаблица ASCII построена таким образом, чтобы распределение кодов отражало функциональное значение символов. Порядок не случаен: управляющие коды идут первыми, за ними — пробел, цифры, буквы и специальные знаки. Такое расположение облегчает сортировку, поиск, редактирование и работу с текстом в программном обеспечении. Благодаря логичной структуре таблица остаётся удобной для анализа даже спустя десятилетия после создания.\n\n### Деление на диапазоны\n\n| Диапазон | Назначение |\n|:---------|:------------------------|\n| 0–31 | Управляющие команды |\n| 32 | Пробел |\n| 33–47 | Знаки препинания |\n| 48–57 | Цифры |\n| 58–64 | Дополнительные знаки |\n| 65–90 | Заглавные буквы |\n| 91–96 | Скобки и символы |\n| 97–122 | Строчные буквы |\n| 123–126 | Фигурные скобки, тильда |\n| 127 | Удаление |\n\n### Разница между регистрами\n\nЗаглавные и строчные буквы различаются на 32 единицы в десятичной системе. Это свойство используется в программах для преобразования регистра:\n\n```python\n# Python: разница в кодах\n\nord('a') - ord('A') # 32\n```\n\nТакое упорядочение упрощает сортировку и поиск по алфавиту.\n\n## Расширения ASCII\n\nСо временем базового диапазона ASCII стало недостаточно. Развитие международных вычислительных систем и увеличение числа языков, использующих нелатинские алфавиты, потребовали расширения набора символов. Стандарт из 128 позиций покрывал только английский язык и основные знаки препинания, что ограничивало его применимость в глобальной среде. При этом сохранялась необходимость совместимости со старыми системами, поэтому разработчики выбрали путь расширения таблицы, а не создания нового стандарта.\n\n### Extended ASCII\n\nБазовый диапазон 0–127 был дополнен новыми символами, образовав 8-битный набор 0–255. Расширенные версии получили общее название Extended ASCII. Они включали буквы с диакритикой, символы национальных алфавитов, графические и служебные элементы.\n\nНаиболее распространённые варианты:\n\n* ISO 8859-1 (Latin-1) — охватывает языки Западной Европы;\n\n* Windows-1252 — версия Microsoft с типографскими кавычками, знаком евро и дополнительными символами;\n\n* Mac Roman — использовалась в старых операционных системах Apple.\n\nКлючевым принципом расширенных кодировок стала обратная совместимость: первые 128 позиций полностью совпадали с оригинальной таблицей ASCII. Это гарантировало корректную работу старых программ при обработке новых текстов.\n\nОднако появление множества вариаций породило новую проблему — несовместимость между ними. Один и тот же байт в разных кодировках мог обозначать разные символы, что приводило к искажению текста при передаче между системами. Например, код 0x80 в Windows-1252 соответствует типографской кавычке, а в ISO 8859-1 не используется вовсе. Эта ситуация сделала невозможным создание единой международной текстовой среды.\n\n### Национальные варианты\n\nВ разных странах появились собственные расширения.\n\n* В СССР и России — KOI8-R и CP866, обеспечивавшие поддержку кириллицы;\n\n* В Восточной Европе — ISO 8859-2 для польского, чешского и венгерского языков;\n\n* В Азии — локальные кодировки для японского, китайского и корейского письма.\n\nНесмотря на адаптацию к национальным алфавитам, эти кодировки не были совместимы между собой. Один и тот же документ мог отображаться по-разному на разных устройствах, что усложняло международный обмен данными.\n\n### Ограничения\n\nРасширенные наборы отличались расположением символов и правилами интерпретации байтов. Один код мог обозначать разные буквы в разных системах, что делало невозможным универсальную обработку текстов. Эта проблема стала главным стимулом для перехода к универсальному стандарту Unicode, охватывающему все письменности мира и сохраняющему совместимость с ASCII в первых 128 кодах.\n\n## ASCII в программировании\n\nASCII — базовая кодировка для большинства языков программирования. Любой символ можно преобразовать в число и обратно:\n\n```python\nprint(ord('A')) # 65\nprint(chr(97)) # a\n```\n\nВ языке C:\n\n```c\n#include <stdio.h>\n\nint main() {\n printf("%d\\n", 'A'); // 65\n printf("%c\\n", 97); // a\n return 0;\n}\n```\n\nЭти функции используются при обработке строк, шифровании, анализе протоколов и разработке терминальных интерфейсов.\n\n### Escape-последовательности\n\nУправляющие символы в программировании записываются через обратный слэш:\n\n* `\\n` — перевод строки (LF, код 10);\n* `\\r` — возврат каретки (CR, код 13);\n* `\\t` — табуляция (TAB, код 9);\n* `\\b` — шаг назад (BS, код 8).\n\nЭти комбинации позволяют форматировать текст при выводе и управлять позиционированием курсора.\n\n## ASCII в практике\n\nНесмотря на появление Unicode и множества современных кодировок, ASCII продолжает использоваться в тысячах программных и аппаратных систем по всему миру. Его простота, минимальные требования к ресурсам и абсолютная совместимость делают стандарт идеальным для базового обмена текстовой информацией. ASCII остаётся неотъемлемой частью архитектуры сетевых протоколов, операционных систем, микроконтроллеров и конфигурационных файлов.\nВ большинстве случаев именно ASCII лежит в основе служебных структур данных, системных логов и коммуникаций между устройствами.\n\n### Применение в системах\n\n1. Текстовые файлы — базовые форматы .txt, .ini, .cfg, .log и конфигурационные документы используют только ASCII-символы, что обеспечивает их универсальное чтение в любой среде.\n\n2. Сетевые протоколы — команды, заголовки и ответы в HTTP, SMTP, FTP, POP3, IMAP оформляются в виде строк ASCII, что гарантирует читаемость и стабильность работы протоколов на разных платформах.\n\n3. Терминалы и консоли — интерфейсы UNIX, Linux и Windows CMD передают команды и результаты выполнения в ASCII-потоках, обеспечивая совместимость между оболочками и удалёнными серверами.\n\n4. Встраиваемые системы — микроконтроллеры, промышленные контроллеры и IoT-устройства хранят параметры и диагностические данные в текстовом ASCII-формате для упрощения отладки и взаимодействия с инженерным ПО.\n\n### ASCII art и креативные применения\n\nASCII применяется и за пределами программирования. Художники создают изображения, используя символы как пиксели. Примеры таких работ используются в логотипах, баннерах, ретро-играх и генераторах текста. Этот вид искусства сохраняет популярность благодаря минимализму и совместимости с любым терминалом.\n\n## ASCII и Unicode\n\nРазвитие компьютерных систем и рост глобальных коммуникаций потребовали кодировки, способной охватывать не только латиницу, но и все мировые письменности. К началу 1990-х годов стало очевидно, что набор ASCII, включающий всего 128 символов, не справляется с этой задачей. Возникла потребность в универсальном стандарте, объединяющем национальные алфавиты и технические символы, но при этом совместимом с уже существующими системами.\nТак появился Unicode — логическое продолжение ASCII, расширившее его принципы до глобального масштаба. Unicode стал основой современной цифровой коммуникации, сохранив при этом преемственность с оригинальным стандартом.\n\n### Отличия и совместимость\n\nUnicode — расширение идей ASCII. В нём предусмотрено более двух миллионов кодовых позиций, охватывающих все известные письменности, математические и технические знаки, пиктограммы и эмодзи. Первые 128 кодов полностью совпадают с таблицей ASCII, что обеспечивает полную обратную совместимость.\n\nКодировки UTF-8, UTF-16 и UTF-32 реализуют разные способы хранения символов Unicode в памяти и передаче данных. Наиболее распространённой стала UTF-8, так как она сохраняет однобайтовое представление для символов ASCII и использует больше байтов только при необходимости.\n\n### Почему Unicode не вытеснил ASCII\n\nНесмотря на универсальность Unicode, ASCII остаётся востребованным в областях, где важны простота, стабильность и минимальный размер данных.\n\nПреимущества ASCII:\n\n* минимальный размер символа — 1 байт;\n\n* высокая скорость обработки;\n\n* совместимость с устаревшими и встроенными протоколами;\n\n* устойчивость на всех платформах и в любых языках программирования.\n\nUnicode применяется для многоязычных систем, веб\\-приложений и документов, где требуется поддержка различных алфавитов. ASCII продолжает использоваться в базовых служебных структурах, системном программировании, логах, сетевых заголовках и текстовых протоколах, где производительность и надёжность важнее универсальности.\n\n## Таблица символов ASCII (0–127)\n\n| DEC | HEX | Символ | Назначение |\n|-------|-------|-------------------------------|--------------------------|\n| 0 | 0 | NUL | Null |\n| 1 | 1 | SOH | Start of Heading |\n| 2 | 2 | STX | Start of Text |\n| 3 | 3 | ETX | End of Text |\n| 4 | 4 | EOT | End of Transmission |\n| 5 | 5 | ENQ | Enquiry |\n| 6 | 6 | ACK | Acknowledge |\n| 7 | 7 | BEL | Звуковой сигнал |\n| 8 | 8 | BS | Backspace |\n| 9 | 9 | TAB | Горизонтальная табуляция |\n| 10 | 0A | LF | Перевод строки |\n| 11 | 0B | VT | Вертикальная табуляция |\n| 12 | 0C | FF | Прогон страницы |\n| 13 | 0D | CR | Возврат каретки |\n| 14 | 0E | SO | Shift Out |\n| 15 | 0F | SI | Shift In |\n| 16–31 | 10–1F | — | Управляющие коды |\n| 32 | 20 | (Space) | Пробел |\n| 33–47 | 21–2F | ! " # $ % & ' ( ) * + , - . / | Знаки препинания |\n| 48–57 | 30–39 | 0–9 | Цифры |\n| 58–64 | 3A–40 | : ; < = > ? @ | Символы |\n| 65–90 | 41–5A | A–Z | Заглавные буквы |\n| 91–96 | 5B–60 | [ \\ ] ^ _ ` | Скобки и служебные |\n| 97–122 | 61–7A | a–z | Строчные буквы |\n| 123–126 | 7B–7E | { | } ~ |\n| 127 | 7F | DEL | Удаление |\n\n\nЭта таблица образует минимальный набор символов, поддерживаемый всеми системами без исключения.\n\n## Преимущества и ограничения ASCII\n\nПосле десятилетий использования ASCII остаётся одним из самых устойчивых стандартов в сфере информационных технологий. Его принципы просты, но именно эта простота обеспечила долговечность и совместимость с современными системами. При этом у стандарта есть объективные пределы, обусловленные историческими ограничениями его разработки. Рассмотрим сильные стороны и недостатки ASCII с позиции современного ИТ-контекста.\n\n### Преимущества\n\n* Простая структура и лёгкая реализация.\n\n* Полная совместимость между устройствами, операционными системами и протоколами.\n\n* Небольшой объём данных — каждый символ занимает 1 байт.\n\n* Надёжность и устойчивость при передаче информации в любых сетях.\n\n* Базовая совместимость с Unicode и его подмножествами (первые 128 кодов полностью совпадают).\n\nБлагодаря этим свойствам ASCII до сих пор используется как внутренний формат системных утилит, терминалов, микроконтроллеров и текстовых протоколов, где минимализм и предсказуемость критически важны.\n\n### Ограничения\n\n* Всего 128 символов — недостаточно для национальных алфавитов и расширенных наборов знаков.\n\n* Отсутствие поддержки диакритики, символов валют, графических элементов и специальных обозначений.\n\n* Невозможность прямого применения в многоязычных и контентных системах.\n\n* Проблемы совместимости при переходе на расширенные версии и другие локальные кодировки.\n\nНесмотря на это, ASCII остаётся основой большинства современных текстовых форматов. Такие технологии, как HTML, XML, JSON, CSV, используют ASCII в качестве базового слоя представления данных, а Unicode — лишь как надстройку для дополнительных символов. Это доказывает, что даже в эпоху глобальных стандартов минимализм ASCII продолжает обеспечивать стабильность цифрового обмена.\n","datePublished":"2025-11-18T15:01:56.210Z","upvoteCount":1,"author":{"@type":"Person","name":"Nikolai Gagarinov"},"url":"https://ru.hexlet.io/qna/glossary/questions/chto-takoe-ascii#answer-5158"},"suggestedAnswer":[{"@type":"Answer","text":"ASCII (American Standard Code for Information Interchange) - это таблица символов, которая используется для представления букв, цифр и других символов в виде чисел. ASCII используется в большинстве компьютерных систем и является основой для других кодировок, таких как UTF-8 и UTF-16.","datePublished":"2023-11-16T20:24:20.362Z","upvoteCount":0,"author":{"@type":"Person","name":"Елена Редькина"},"url":"https://ru.hexlet.io/qna/glossary/questions/chto-takoe-ascii#answer-3301"}]}}</script><div style="--container-size:var(--container-size-lg);margin-top:var(--mantine-spacing-xl);height:100%" class="m_7485cace mantine-Container-root" data-size="lg" data-strategy="block"><script type="application/ld+json">{"@context":"https://schema.org","@type":"BreadcrumbList","itemListElement":[{"position":1,"@type":"ListItem","item":{"@id":"/qna","name":"Вопросы и ответы"}},{"position":2,"@type":"ListItem","item":{"@id":"/qna/glossary/questions","name":"Глоссарий"}},{"position":3,"@type":"ListItem","item":{"@id":"/qna/glossary/questions/chto-takoe-ascii","name":"ASCII"}}]}</script><div style="margin-bottom:var(--mantine-spacing-xs)" class="m_8b3717df mantine-Breadcrumbs-root"><a style="--text-fz:var(--mantine-font-size-sm);--text-lh:var(--mantine-line-height-sm);white-space:normal;color:inherit" class="mantine-focus-auto m_849cf0da m_f678d540 mantine-Breadcrumbs-breadcrumb m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-size="sm" data-underline="hover" href="/"><div style="color:inherit" class="m_4451eb3a mantine-Center-root"><svg xmlns="http://www.w3.org/2000/svg" width="15" height="15" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-home-link "><path d="M20.085 11.085l-8.085 -8.085l-9 9h2v7a2 2 0 0 0 2 2h4.5"></path><path d="M9 21v-6a2 2 0 0 1 2 -2h2a2 2 0 0 1 1.807 1.143"></path><path d="M20 21a1 1 0 1 0 2 0a1 1 0 1 0 -2 0"></path><path d="M20 16a1 1 0 1 0 2 0a1 1 0 1 0 -2 0"></path><path d="M15 19a1 1 0 1 0 2 0a1 1 0 1 0 -2 0"></path><path d="M21 16l-5 3l5 2"></path></svg></div></a><div class="m_3b8f2208 mantine-Breadcrumbs-separator">/</div><a style="--text-fz:var(--mantine-font-size-sm);--text-lh:var(--mantine-line-height-sm);white-space:normal;color:inherit" class="mantine-focus-auto m_849cf0da m_f678d540 mantine-Breadcrumbs-breadcrumb m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-size="sm" data-underline="hover" href="/qna">Вопросы и ответы</a><div class="m_3b8f2208 mantine-Breadcrumbs-separator">/</div><a style="--text-fz:var(--mantine-font-size-sm);--text-lh:var(--mantine-line-height-sm);white-space:normal;color:inherit" class="mantine-focus-auto m_849cf0da m_f678d540 mantine-Breadcrumbs-breadcrumb m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-size="sm" data-underline="hover" href="/qna/glossary/questions">Глоссарий</a><div class="m_3b8f2208 mantine-Breadcrumbs-separator">/</div><p style="--text-fz:var(--mantine-font-size-sm);--text-lh:var(--mantine-line-height-sm);white-space:normal;color:var(--mantine-color-dimmed)" class="mantine-focus-auto m_f678d540 mantine-Breadcrumbs-breadcrumb m_b6d8b162 mantine-Text-root" data-size="sm">ASCII</p></div><style data-mantine-styles="inline">.__m__-_R_eub_{margin-bottom:var(--mantine-spacing-xs);}@media(min-width: 36em){.__m__-_R_eub_{margin-bottom:var(--mantine-spacing-xs);}}</style><div style="--group-gap:var(--mantine-spacing-md);--group-align:center;--group-justify:space-between;--group-wrap:wrap" class="m_4081bf90 mantine-Group-root __m__-_R_eub_"><style data-mantine-styles="inline">.__m__-_R_deub_{width:100%;}@media(min-width: 36em){.__m__-_R_deub_{width:70%;}}@media(min-width: 75em){.__m__-_R_deub_{width:75%;}}</style><div class="__m__-_R_deub_"><div style="--group-gap:var(--mantine-spacing-md);--group-align:center;--group-justify:start;--group-wrap:nowrap" class="m_4081bf90 mantine-Group-root"><h1 style="--title-fw:var(--mantine-h1-font-weight);--title-lh:var(--mantine-h1-line-height);--title-fz:var(--mantine-h1-font-size)" class="m_8a5d1357 mantine-Title-root" data-order="1">ASCII</h1></div></div></div><style data-mantine-styles="inline">.__m__-_R_iub_{--grid-gutter:var(--mantine-spacing-md);}</style><div class="m_410352e9 mantine-Grid-root __m__-_R_iub_"><div class="m_dee7bd2f mantine-Grid-inner"><style data-mantine-styles="inline">.__m__-_R_3diub_{--col-flex-grow:auto;--col-flex-basis:100%;--col-max-width:100%;}@media(min-width: 48em){.__m__-_R_3diub_{--col-flex-grow:auto;--col-flex-basis:83.33333333333334%;--col-max-width:83.33333333333334%;}}@media(min-width: 62em){.__m__-_R_3diub_{--col-flex-grow:auto;--col-flex-basis:66.66666666666667%;--col-max-width:66.66666666666667%;}}</style><div class="m_96bdd299 mantine-Grid-col __m__-_R_3diub_"><div style="--group-gap:var(--mantine-spacing-md);--group-align:center;--group-justify:flex-start;--group-wrap:wrap;margin-bottom:var(--mantine-spacing-lg)" class="m_4081bf90 mantine-Group-root"></div><div style="--group-gap:var(--mantine-spacing-md);--group-align:center;--group-justify:flex-start;--group-wrap:wrap;margin-bottom:var(--mantine-spacing-xl);font-size:var(--mantine-font-size-sm)" class="m_4081bf90 mantine-Group-root"><div style="--group-gap:calc(0.25rem * var(--mantine-scale));--group-align:center;--group-justify:flex-start;--group-wrap:wrap;margin-inline-start:auto" class="m_4081bf90 mantine-Group-root"><svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-calendar "><path d="M4 7a2 2 0 0 1 2 -2h12a2 2 0 0 1 2 2v12a2 2 0 0 1 -2 2h-12a2 2 0 0 1 -2 -2v-12"></path><path d="M16 3v4"></path><path d="M8 3v4"></path><path d="M4 11h16"></path><path d="M11 15h1"></path><path d="M12 15v3"></path></svg><p class="mantine-focus-auto m_b6d8b162 mantine-Text-root" data-inherit="true">3 года назад</p></div><div style="--group-gap:calc(0.25rem * var(--mantine-scale));--group-align:center;--group-justify:flex-start;--group-wrap:wrap" class="m_4081bf90 mantine-Group-root"><svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-user "><path d="M8 7a4 4 0 1 0 8 0a4 4 0 0 0 -8 0"></path><path d="M6 21v-2a4 4 0 0 1 4 -4h4a4 4 0 0 1 4 4v2"></path></svg><p class="mantine-focus-auto m_b6d8b162 mantine-Text-root" data-inherit="true">Nikolai Gagarinov</p></div></div><div role="link" tabindex="0" style="cursor:pointer"><button style="display:block;width:100%" class="mantine-focus-auto m_87cf2631 mantine-UnstyledButton-root" type="button" aria-label="Присоединяйтесь к нашему Telegram-сообществу"><div style="background-color:light-dark(var(--mantine-color-gray-1), var(--mantine-color-dark-6));margin-block:var(--mantine-spacing-xs)" class="m_e615b15f mantine-Card-root m_1b7284a3 mantine-Paper-root"><div style="--group-gap:var(--mantine-spacing-md);--group-align:center;--group-justify:flex-start;--group-wrap:wrap" class="m_4081bf90 mantine-Group-root"><div style="--ti-bg:transparent;--ti-color:var(--mantine-color-indigo-light-color);--ti-bd:calc(0.0625rem * var(--mantine-scale)) solid transparent;margin-inline-end:auto;color:inherit" class="m_7341320d mantine-ThemeIcon-root" data-variant="transparent"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="1.2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-brand-telegram "><path d="M15 10l-4 4l6 6l4 -16l-18 7l4 2l2 6l3 -4"></path></svg></div>Присоединяйтесь к нашему Telegram-сообществу</div></div></button></div><h2 style="--title-fw:var(--mantine-h2-font-weight);--title-lh:var(--mantine-h2-line-height);--title-fz:var(--mantine-h2-font-size);margin-block:var(--mantine-spacing-xl)" class="m_8a5d1357 mantine-Title-root" data-order="2">Ответы</h2><div style="margin-bottom:var(--mantine-spacing-xl);padding:var(--mantine-spacing-lg)" class="m_e615b15f mantine-Card-root m_1b7284a3 mantine-Paper-root" data-with-border="true" id="answer-5158"><div style="--group-gap:calc(1.125rem * var(--mantine-scale));--group-align:stretch;--group-justify:flex-start;--group-wrap:nowrap" class="m_4081bf90 mantine-Group-root"><div style="--stack-gap:var(--mantine-spacing-md);--stack-align:stretch;--stack-justify:flex-start;font-size:var(--mantine-font-size-h1);font-weight:lighter;text-align:center" class="m_6d731127 mantine-Stack-root">1<a style="color:inherit" class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/qna/glossary/questions/chto-takoe-ascii/answers/5158/vote"><div style="--ti-bg:transparent;--ti-color:var(--mantine-color-indigo-light-color);--ti-bd:calc(0.0625rem * var(--mantine-scale)) solid transparent;color:inherit" class="m_7341320d mantine-ThemeIcon-root" data-variant="transparent"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-thumb-up "><path d="M7 11v8a1 1 0 0 1 -1 1h-2a1 1 0 0 1 -1 -1v-7a1 1 0 0 1 1 -1h3a4 4 0 0 0 4 -4v-1a2 2 0 0 1 4 0v5h3a2 2 0 0 1 2 2l-1 5a2 3 0 0 1 -2 2h-7a3 3 0 0 1 -3 -3"></path></svg></div></a><div style="--ti-bg:transparent;--ti-color:var(--mantine-color-indigo-light-color);--ti-bd:calc(0.0625rem * var(--mantine-scale)) solid transparent;color:inherit" class="m_7341320d mantine-ThemeIcon-root" data-variant="transparent"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-check "><path d="M5 12l5 5l10 -10"></path></svg></div></div><div style="--stack-gap:var(--mantine-spacing-md);--stack-align:stretch;--stack-justify:flex-start;width:100%;min-width:0rem" class="m_6d731127 mantine-Stack-root"><div style="margin-bottom:auto" class="m_d08caa0 mantine-Typography-root"><p>ASCII (American Standard Code for Information Interchange) — американский стандарт кодирования символов, разработанный для обмена текстовой информацией между устройствами и программами. В таблице определено 128 позиций (0-127), где каждой букве, цифре, знаку препинания или управляющей команде соответствует числовое значение.</p>
<p>Этот стандарт стал универсальной системой представления текста в цифровом виде и заложил фундамент для всех последующих кодировок, включая Unicode. Его принципы до сих пор применяются в операционных системах, языках программирования и сетевых протоколах.</p>
<p><img style="--image-object-fit:contain;width:auto" class="m_9e117634 mantine-Image-root" src="https://cdn6.hexlet.io/SmMdo8y4yk6Z.png" alt="image" loading="lazy"/></p>
<p>ASCII описывает систему, где каждый символ представлен числовым кодом. Компьютеры оперируют не знаками, а числами, поэтому кодировка обеспечивает взаимопонимание между устройствами.</p>
<p>Пример числовых соответствий:</p>
<ul>
<li>
<p>A — 65</p>
</li>
<li>
<p>a — 97</p>
</li>
<li>
<p>пробел — 32</p>
</li>
<li>
<p>0 — 48</p>
</li>
</ul>
<p>Благодаря единой таблице любой символ читается одинаково на разных платформах. Этот принцип стал ключевым для развития вычислительной техники и сетевых коммуникаций.</p>
<h2 id="heading-2-1">Краткая суть и значение в истории IT</h2>
<p>Появление ASCII стало поворотным моментом в истории ИТ. До его утверждения каждый производитель применял собственные таблицы символов, из-за чего данные, переданные с одного устройства, могли отображаться некорректно на другом.</p>
<p>ASCII впервые установил единые правила, сделав возможным массовый обмен информацией между несовместимыми ранее системами. Этот шаг превратил текст в универсальную форму данных и стал основой для развития телекоммуникаций, программирования и компьютерных сетей.</p>
<h3 id="heading-3-2">История появления</h3>
<p>ASCII возник не как случайное изобретение, а как необходимость — ответ на стремительное развитие телекоммуникаций и вычислительной техники середины XX века. Переход от аналоговой связи к цифровой требовал унифицированного языка, который понимали бы и машины, и операторы. Этот язык должен был быть простым, компактным и пригодным для любых устройств, от телетайпов до первых компьютеров.</p>
<h3 id="heading-3-3">Контекст 1960-х</h3>
<p>В послевоенные годы активно использовались телетайпы — электромеханические машины, способные печатать сообщения, передаваемые по телефонным линиям. Они заменяли телеграф и использовались в армии, авиации, банках и редакциях газет. Каждая модель имела собственный набор кодов: Baudot, Murray, ITA2, позднее — внутренние таблицы производителей вроде Western Electric или Teletype Corporation.</p>
<p>Такая разрозненность вызывала постоянные ошибки: одни и те же байты трактовались как разные символы, данные терялись или искажались.</p>
<p>К началу 1960-х стало очевидно, что требуются единые стандарты передачи текстовой информации. К этому времени появлялись первые компьютеры, но обмен данными между ними был сложен именно из-за несовместимости кодировок. Кроме того, необходимо было задать не только буквы и цифры, но и управляющие команды, такие как возврат каретки, перевод строки или сигнал завершения передачи. Всё это подтолкнуло инженеров и производителей к созданию общего системного языка символов.</p>
<p>Американская ассоциация стандартов (ASA) сформировала специальный комитет X3.4, куда вошли представители компаний IBM, AT&T, Honeywell и Bell Labs. Их задачей было определить набор символов, достаточный для любых коммуникаций, но при этом компактный, чтобы помещался в байт данных — восемь бит. Первые проекты включали больше 200 символов, однако для простоты систему сократили до 128.</p>
<h3 id="heading-3-4">Организация ANSI и принятие стандарта</h3>
<p>После нескольких лет обсуждений в 1963 году была опубликована первая спецификация ASCII. В документе определялись:</p>
<ul>
<li>
<p>числовые коды для латинских букв, цифр и основных знаков препинания;</p>
</li>
<li>
<p>управляющие символы (NUL, LF, CR, ESC и другие);</p>
</li>
<li>
<p>структура таблицы — 7-битная, что обеспечивало совместимость с восьмибитными системами, где один бит использовался для контроля ошибок.</p>
</li>
</ul>
<p>В 1967 году стандарт получил официальное утверждение от ANSI (American National Standards Institute), сменившего ASA. В 1968 году добавлены последние элементы — вертикальная черта «|» и тильда «~». Этот набор в дальнейшем практически не менялся и используется в неизменном виде до сих пор.</p>
<p>Принятие ASCII совпало с формированием первых компьютерных сетей — ARPANET и коммерческих телекоммуникационных линий. Появился реальный инструмент для унификации обмена текстом между различными вычислительными системами, независимо от производителя и архитектуры.</p>
<p>Кроме того, ASCII стал частью международного стандарта ISO 646, что позволило адаптировать его для разных стран: в национальных версиях некоторые символы заменялись (например, знак доллара на фунт в британском варианте), но основа оставалась общей.</p>
<p>ASCII стал своего рода «латинским алфавитом» для машин — простым, понятным и универсальным языком коммуникации.</p>
<h3 id="heading-3-5">Распространение и применение</h3>
<p>После стандартизации ASCII быстро получил признание индустрии. Он стал основой для развития операционных систем и языков программирования.</p>
<p>В 1970-е годы кодировка внедряется в UNIX, язык C и большинство терминалов того времени. Команды, системные сообщения и текстовые интерфейсы опирались исключительно на ASCII.</p>
<p>Вскоре таблица ASCII стала обязательным элементом компьютерной архитектуры:</p>
<ul>
<li>
<p>микропроцессоры Intel, DEC и Motorola изначально проектировались с учётом ASCII-кодировки;</p>
</li>
<li>
<p>принтеры и модемы использовали её при передаче текстовых данных;</p>
</li>
<li>
<p>протоколы связи (SMTP, FTP, HTTP) строились на текстовых командах, составленных из ASCII-символов.</p>
</li>
</ul>
<p>Например, строки заголовков в письмах электронной почты или HTTP-запросах до сих пор передаются в виде обычного ASCII-текста, что гарантирует читаемость на любых устройствах.</p>
<h2 id="heading-2-6">Принципы кодирования в ASCII</h2>
<p>Любая система обработки данных опирается на способ представления информации в виде чисел. Для компьютера текст — это не набор букв, а совокупность бинарных значений, которые он может хранить, передавать и преобразовывать. Кодировка ASCII устанавливает строгие правила соответствия между символами и их числовыми кодами. Этот подход обеспечивает однозначность интерпретации данных и совместимость между различными устройствами и программами.</p>
<h3 id="heading-3-7">Почему символы кодируются числами</h3>
<p>Цифровые устройства оперируют двоичными значениями (0 и 1). Чтобы компьютер мог обрабатывать текст, символы должны быть представлены в числовом виде. Таблица ASCII задаёт соответствие между символом и его числом. Например, буква A соответствует двоичному коду 01000001.</p>
<h3 id="heading-3-8">Системы представления</h3>
<p>Один и тот же символ можно выразить в трёх формах:</p>
<ul>
<li>
<p>Двоичная: 01000001</p>
</li>
<li>
<p>Десятичная: 65</p>
</li>
<li>
<p>Шестнадцатеричная: 41</p>
</li>
</ul>
<p>Двоичный вид понятен машине, десятичный — человеку, а шестнадцатеричный удобен при отладке и анализе.</p>
<h3 id="heading-3-9">Управляющие и печатные символы</h3>
<p>Первые 32 кода (0–31) — управляющие. Они не имеют графического отображения и используются для сигналов «перевод строки», «звонок», «возврат каретки» и т. д.</p>
<p>Коды 32–126 — печатные символы: буквы, цифры и знаки препинания. Код 127 — DEL, удаление символа.</p>
<p>Такое разделение позволило описывать не только текст, но и процессы его вывода на экран или печать.</p>
<p><img style="--image-object-fit:contain;width:auto" class="m_9e117634 mantine-Image-root" src="https://cdn6.hexlet.io/v2VaNcpfZzqn.png" alt="ascii table" loading="lazy"/></p>
<h2 id="heading-2-10">Структура таблицы ASCII</h2>
<p>Таблица ASCII построена таким образом, чтобы распределение кодов отражало функциональное значение символов. Порядок не случаен: управляющие коды идут первыми, за ними — пробел, цифры, буквы и специальные знаки. Такое расположение облегчает сортировку, поиск, редактирование и работу с текстом в программном обеспечении. Благодаря логичной структуре таблица остаётся удобной для анализа даже спустя десятилетия после создания.</p>
<h3 id="heading-3-11">Деление на диапазоны</h3>
<div style="--table-min-width:calc(50rem * var(--mantine-scale));--sa-corner-width:0px;--sa-corner-height:0px" class="m_a100c15 mantine-TableScrollContainer-scrollContainer m_d57069b5 mantine-ScrollArea-root"><div style="overflow-x:hidden;overflow-y:hidden" class="m_c0783ff9 mantine-ScrollArea-viewport" data-offset-scrollbars="x" data-scrollbars="xy"><div class="m_b1336c6 mantine-ScrollArea-content"><div class="m_62259741 mantine-TableScrollContainer-scrollContainerInner"><table><thead><tr><th style="text-align:left">Диапазон</th><th style="text-align:left">Назначение</th></tr></thead><tbody><tr><td style="text-align:left">0–31</td><td style="text-align:left">Управляющие команды</td></tr><tr><td style="text-align:left">32</td><td style="text-align:left">Пробел</td></tr><tr><td style="text-align:left">33–47</td><td style="text-align:left">Знаки препинания</td></tr><tr><td style="text-align:left">48–57</td><td style="text-align:left">Цифры</td></tr><tr><td style="text-align:left">58–64</td><td style="text-align:left">Дополнительные знаки</td></tr><tr><td style="text-align:left">65–90</td><td style="text-align:left">Заглавные буквы</td></tr><tr><td style="text-align:left">91–96</td><td style="text-align:left">Скобки и символы</td></tr><tr><td style="text-align:left">97–122</td><td style="text-align:left">Строчные буквы</td></tr><tr><td style="text-align:left">123–126</td><td style="text-align:left">Фигурные скобки, тильда</td></tr><tr><td style="text-align:left">127</td><td style="text-align:left">Удаление</td></tr></tbody></table></div></div></div></div>
<h3 id="heading-3-12">Разница между регистрами</h3>
<p>Заглавные и строчные буквы различаются на 32 единицы в десятичной системе. Это свойство используется в программах для преобразования регистра:</p>
<div style="margin-bottom:var(--mantine-spacing-lg)" class="m_e597c321 mantine-CodeHighlight-codeHighlight" dir="ltr"><div class="m_be7e9c9c mantine-CodeHighlight-controls"><button style="--ai-bg:transparent;--ai-hover:transparent;--ai-color:inherit;--ai-bd:none" class="mantine-focus-auto mantine-active m_d498bab7 mantine-CodeHighlight-control m_8d3f4000 mantine-ActionIcon-root m_87cf2631 mantine-UnstyledButton-root" data-variant="none" type="button" aria-label="Copy code"><span class="m_8d3afb97 mantine-ActionIcon-icon"><svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24" stroke-width="2" stroke="currentColor" fill="none" stroke-linecap="round" stroke-linejoin="round"><path stroke="none" d="M0 0h24v24H0z" fill="none"></path><path d="M8 8m0 2a2 2 0 0 1 2 -2h8a2 2 0 0 1 2 2v8a2 2 0 0 1 -2 2h-8a2 2 0 0 1 -2 -2z"></path><path d="M16 8v-2a2 2 0 0 0 -2 -2h-8a2 2 0 0 0 -2 2v8a2 2 0 0 0 2 2h2"></path></svg></span></button></div><div style="--scrollarea-scrollbar-size:calc(0.25rem * var(--mantine-scale));--sa-corner-width:0px;--sa-corner-height:0px" class="m_f744fd40 mantine-CodeHighlight-scrollarea m_d57069b5 mantine-ScrollArea-root" dir="ltr"><div style="overflow-x:hidden;overflow-y:hidden;overscroll-behavior-inline:none" class="m_c0783ff9 mantine-ScrollArea-viewport" data-scrollbars="xy"><div class="m_b1336c6 mantine-ScrollArea-content"><pre class="m_2c47c4fd mantine-CodeHighlight-pre" style="padding:0"><code class="m_5caae6d3 mantine-CodeHighlight-code"># Python: разница в кодах
ord('a') - ord('A') # 32</code></pre></div></div></div><button class="mantine-focus-auto m_c9378bc2 mantine-CodeHighlight-showCodeButton m_87cf2631 mantine-UnstyledButton-root" data-hidden="true" type="button">Expand code</button></div>
<p>Такое упорядочение упрощает сортировку и поиск по алфавиту.</p>
<h2 id="heading-2-13">Расширения ASCII</h2>
<p>Со временем базового диапазона ASCII стало недостаточно. Развитие международных вычислительных систем и увеличение числа языков, использующих нелатинские алфавиты, потребовали расширения набора символов. Стандарт из 128 позиций покрывал только английский язык и основные знаки препинания, что ограничивало его применимость в глобальной среде. При этом сохранялась необходимость совместимости со старыми системами, поэтому разработчики выбрали путь расширения таблицы, а не создания нового стандарта.</p>
<h3 id="heading-3-14">Extended ASCII</h3>
<p>Базовый диапазон 0–127 был дополнен новыми символами, образовав 8-битный набор 0–255. Расширенные версии получили общее название Extended ASCII. Они включали буквы с диакритикой, символы национальных алфавитов, графические и служебные элементы.</p>
<p>Наиболее распространённые варианты:</p>
<ul>
<li>
<p>ISO 8859-1 (Latin-1) — охватывает языки Западной Европы;</p>
</li>
<li>
<p>Windows-1252 — версия Microsoft с типографскими кавычками, знаком евро и дополнительными символами;</p>
</li>
<li>
<p>Mac Roman — использовалась в старых операционных системах Apple.</p>
</li>
</ul>
<p>Ключевым принципом расширенных кодировок стала обратная совместимость: первые 128 позиций полностью совпадали с оригинальной таблицей ASCII. Это гарантировало корректную работу старых программ при обработке новых текстов.</p>
<p>Однако появление множества вариаций породило новую проблему — несовместимость между ними. Один и тот же байт в разных кодировках мог обозначать разные символы, что приводило к искажению текста при передаче между системами. Например, код 0x80 в Windows-1252 соответствует типографской кавычке, а в ISO 8859-1 не используется вовсе. Эта ситуация сделала невозможным создание единой международной текстовой среды.</p>
<h3 id="heading-3-15">Национальные варианты</h3>
<p>В разных странах появились собственные расширения.</p>
<ul>
<li>
<p>В СССР и России — KOI8-R и CP866, обеспечивавшие поддержку кириллицы;</p>
</li>
<li>
<p>В Восточной Европе — ISO 8859-2 для польского, чешского и венгерского языков;</p>
</li>
<li>
<p>В Азии — локальные кодировки для японского, китайского и корейского письма.</p>
</li>
</ul>
<p>Несмотря на адаптацию к национальным алфавитам, эти кодировки не были совместимы между собой. Один и тот же документ мог отображаться по-разному на разных устройствах, что усложняло международный обмен данными.</p>
<h3 id="heading-3-16">Ограничения</h3>
<p>Расширенные наборы отличались расположением символов и правилами интерпретации байтов. Один код мог обозначать разные буквы в разных системах, что делало невозможным универсальную обработку текстов. Эта проблема стала главным стимулом для перехода к универсальному стандарту Unicode, охватывающему все письменности мира и сохраняющему совместимость с ASCII в первых 128 кодах.</p>
<h2 id="heading-2-17">ASCII в программировании</h2>
<p>ASCII — базовая кодировка для большинства языков программирования. Любой символ можно преобразовать в число и обратно:</p>
<div style="margin-bottom:var(--mantine-spacing-lg)" class="m_e597c321 mantine-CodeHighlight-codeHighlight" dir="ltr"><div class="m_be7e9c9c mantine-CodeHighlight-controls"><button style="--ai-bg:transparent;--ai-hover:transparent;--ai-color:inherit;--ai-bd:none" class="mantine-focus-auto mantine-active m_d498bab7 mantine-CodeHighlight-control m_8d3f4000 mantine-ActionIcon-root m_87cf2631 mantine-UnstyledButton-root" data-variant="none" type="button" aria-label="Copy code"><span class="m_8d3afb97 mantine-ActionIcon-icon"><svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24" stroke-width="2" stroke="currentColor" fill="none" stroke-linecap="round" stroke-linejoin="round"><path stroke="none" d="M0 0h24v24H0z" fill="none"></path><path d="M8 8m0 2a2 2 0 0 1 2 -2h8a2 2 0 0 1 2 2v8a2 2 0 0 1 -2 2h-8a2 2 0 0 1 -2 -2z"></path><path d="M16 8v-2a2 2 0 0 0 -2 -2h-8a2 2 0 0 0 -2 2v8a2 2 0 0 0 2 2h2"></path></svg></span></button></div><div style="--scrollarea-scrollbar-size:calc(0.25rem * var(--mantine-scale));--sa-corner-width:0px;--sa-corner-height:0px" class="m_f744fd40 mantine-CodeHighlight-scrollarea m_d57069b5 mantine-ScrollArea-root" dir="ltr"><div style="overflow-x:hidden;overflow-y:hidden;overscroll-behavior-inline:none" class="m_c0783ff9 mantine-ScrollArea-viewport" data-scrollbars="xy"><div class="m_b1336c6 mantine-ScrollArea-content"><pre class="m_2c47c4fd mantine-CodeHighlight-pre" style="padding:0"><code class="m_5caae6d3 mantine-CodeHighlight-code">print(ord('A')) # 65
print(chr(97)) # a</code></pre></div></div></div><button class="mantine-focus-auto m_c9378bc2 mantine-CodeHighlight-showCodeButton m_87cf2631 mantine-UnstyledButton-root" data-hidden="true" type="button">Expand code</button></div>
<p>В языке C:</p>
<div style="margin-bottom:var(--mantine-spacing-lg)" class="m_e597c321 mantine-CodeHighlight-codeHighlight" dir="ltr"><div class="m_be7e9c9c mantine-CodeHighlight-controls"><button style="--ai-bg:transparent;--ai-hover:transparent;--ai-color:inherit;--ai-bd:none" class="mantine-focus-auto mantine-active m_d498bab7 mantine-CodeHighlight-control m_8d3f4000 mantine-ActionIcon-root m_87cf2631 mantine-UnstyledButton-root" data-variant="none" type="button" aria-label="Copy code"><span class="m_8d3afb97 mantine-ActionIcon-icon"><svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24" stroke-width="2" stroke="currentColor" fill="none" stroke-linecap="round" stroke-linejoin="round"><path stroke="none" d="M0 0h24v24H0z" fill="none"></path><path d="M8 8m0 2a2 2 0 0 1 2 -2h8a2 2 0 0 1 2 2v8a2 2 0 0 1 -2 2h-8a2 2 0 0 1 -2 -2z"></path><path d="M16 8v-2a2 2 0 0 0 -2 -2h-8a2 2 0 0 0 -2 2v8a2 2 0 0 0 2 2h2"></path></svg></span></button></div><div style="--scrollarea-scrollbar-size:calc(0.25rem * var(--mantine-scale));--sa-corner-width:0px;--sa-corner-height:0px" class="m_f744fd40 mantine-CodeHighlight-scrollarea m_d57069b5 mantine-ScrollArea-root" dir="ltr"><div style="overflow-x:hidden;overflow-y:hidden;overscroll-behavior-inline:none" class="m_c0783ff9 mantine-ScrollArea-viewport" data-scrollbars="xy"><div class="m_b1336c6 mantine-ScrollArea-content"><pre class="m_2c47c4fd mantine-CodeHighlight-pre" style="padding:0"><code class="m_5caae6d3 mantine-CodeHighlight-code">#include <stdio.h>
int main() {
printf("%d\n", 'A'); // 65
printf("%c\n", 97); // a
return 0;
}</code></pre></div></div></div><button class="mantine-focus-auto m_c9378bc2 mantine-CodeHighlight-showCodeButton m_87cf2631 mantine-UnstyledButton-root" data-hidden="true" type="button">Expand code</button></div>
<p>Эти функции используются при обработке строк, шифровании, анализе протоколов и разработке терминальных интерфейсов.</p>
<h3 id="heading-3-18">Escape-последовательности</h3>
<p>Управляющие символы в программировании записываются через обратный слэш:</p>
<ul>
<li><code style="margin-bottom:var(--mantine-spacing-lg)" class="m_dfe9c588 mantine-InlineCodeHighlight-inlineCodeHighlight m_e597c321 mantine-CodeHighlight-codeHighlight m_dfe9c588 mantine-InlineCodeHighlight-inlineCodeHighlight">\n</code> — перевод строки (LF, код 10);</li>
<li><code style="margin-bottom:var(--mantine-spacing-lg)" class="m_dfe9c588 mantine-InlineCodeHighlight-inlineCodeHighlight m_e597c321 mantine-CodeHighlight-codeHighlight m_dfe9c588 mantine-InlineCodeHighlight-inlineCodeHighlight">\r</code> — возврат каретки (CR, код 13);</li>
<li><code style="margin-bottom:var(--mantine-spacing-lg)" class="m_dfe9c588 mantine-InlineCodeHighlight-inlineCodeHighlight m_e597c321 mantine-CodeHighlight-codeHighlight m_dfe9c588 mantine-InlineCodeHighlight-inlineCodeHighlight">\t</code> — табуляция (TAB, код 9);</li>
<li><code style="margin-bottom:var(--mantine-spacing-lg)" class="m_dfe9c588 mantine-InlineCodeHighlight-inlineCodeHighlight m_e597c321 mantine-CodeHighlight-codeHighlight m_dfe9c588 mantine-InlineCodeHighlight-inlineCodeHighlight">\b</code> — шаг назад (BS, код 8).</li>
</ul>
<p>Эти комбинации позволяют форматировать текст при выводе и управлять позиционированием курсора.</p>
<h2 id="heading-2-19">ASCII в практике</h2>
<p>Несмотря на появление Unicode и множества современных кодировок, ASCII продолжает использоваться в тысячах программных и аппаратных систем по всему миру. Его простота, минимальные требования к ресурсам и абсолютная совместимость делают стандарт идеальным для базового обмена текстовой информацией. ASCII остаётся неотъемлемой частью архитектуры сетевых протоколов, операционных систем, микроконтроллеров и конфигурационных файлов.
В большинстве случаев именно ASCII лежит в основе служебных структур данных, системных логов и коммуникаций между устройствами.</p>
<h3 id="heading-3-20">Применение в системах</h3>
<ol>
<li>
<p>Текстовые файлы — базовые форматы .txt, .ini, .cfg, .log и конфигурационные документы используют только ASCII-символы, что обеспечивает их универсальное чтение в любой среде.</p>
</li>
<li>
<p>Сетевые протоколы — команды, заголовки и ответы в HTTP, SMTP, FTP, POP3, IMAP оформляются в виде строк ASCII, что гарантирует читаемость и стабильность работы протоколов на разных платформах.</p>
</li>
<li>
<p>Терминалы и консоли — интерфейсы UNIX, Linux и Windows CMD передают команды и результаты выполнения в ASCII-потоках, обеспечивая совместимость между оболочками и удалёнными серверами.</p>
</li>
<li>
<p>Встраиваемые системы — микроконтроллеры, промышленные контроллеры и IoT-устройства хранят параметры и диагностические данные в текстовом ASCII-формате для упрощения отладки и взаимодействия с инженерным ПО.</p>
</li>
</ol>
<h3 id="heading-3-21">ASCII art и креативные применения</h3>
<p>ASCII применяется и за пределами программирования. Художники создают изображения, используя символы как пиксели. Примеры таких работ используются в логотипах, баннерах, ретро-играх и генераторах текста. Этот вид искусства сохраняет популярность благодаря минимализму и совместимости с любым терминалом.</p>
<h2 id="heading-2-22">ASCII и Unicode</h2>
<p>Развитие компьютерных систем и рост глобальных коммуникаций потребовали кодировки, способной охватывать не только латиницу, но и все мировые письменности. К началу 1990-х годов стало очевидно, что набор ASCII, включающий всего 128 символов, не справляется с этой задачей. Возникла потребность в универсальном стандарте, объединяющем национальные алфавиты и технические символы, но при этом совместимом с уже существующими системами.
Так появился Unicode — логическое продолжение ASCII, расширившее его принципы до глобального масштаба. Unicode стал основой современной цифровой коммуникации, сохранив при этом преемственность с оригинальным стандартом.</p>
<h3 id="heading-3-23">Отличия и совместимость</h3>
<p>Unicode — расширение идей ASCII. В нём предусмотрено более двух миллионов кодовых позиций, охватывающих все известные письменности, математические и технические знаки, пиктограммы и эмодзи. Первые 128 кодов полностью совпадают с таблицей ASCII, что обеспечивает полную обратную совместимость.</p>
<p>Кодировки UTF-8, UTF-16 и UTF-32 реализуют разные способы хранения символов Unicode в памяти и передаче данных. Наиболее распространённой стала UTF-8, так как она сохраняет однобайтовое представление для символов ASCII и использует больше байтов только при необходимости.</p>
<h3 id="heading-3-24">Почему Unicode не вытеснил ASCII</h3>
<p>Несмотря на универсальность Unicode, ASCII остаётся востребованным в областях, где важны простота, стабильность и минимальный размер данных.</p>
<p>Преимущества ASCII:</p>
<ul>
<li>
<p>минимальный размер символа — 1 байт;</p>
</li>
<li>
<p>высокая скорость обработки;</p>
</li>
<li>
<p>совместимость с устаревшими и встроенными протоколами;</p>
</li>
<li>
<p>устойчивость на всех платформах и в любых языках программирования.</p>
</li>
</ul>
<p>Unicode применяется для многоязычных систем, веб-приложений и документов, где требуется поддержка различных алфавитов. ASCII продолжает использоваться в базовых служебных структурах, системном программировании, логах, сетевых заголовках и текстовых протоколах, где производительность и надёжность важнее универсальности.</p>
<h2 id="heading-2-25">Таблица символов ASCII (0–127)</h2>
<div style="--table-min-width:calc(50rem * var(--mantine-scale));--sa-corner-width:0px;--sa-corner-height:0px" class="m_a100c15 mantine-TableScrollContainer-scrollContainer m_d57069b5 mantine-ScrollArea-root"><div style="overflow-x:hidden;overflow-y:hidden" class="m_c0783ff9 mantine-ScrollArea-viewport" data-offset-scrollbars="x" data-scrollbars="xy"><div class="m_b1336c6 mantine-ScrollArea-content"><div class="m_62259741 mantine-TableScrollContainer-scrollContainerInner"><table><thead><tr><th>DEC</th><th>HEX</th><th>Символ</th><th>Назначение</th></tr></thead><tbody><tr><td>0</td><td>0</td><td>NUL</td><td>Null</td></tr><tr><td>1</td><td>1</td><td>SOH</td><td>Start of Heading</td></tr><tr><td>2</td><td>2</td><td>STX</td><td>Start of Text</td></tr><tr><td>3</td><td>3</td><td>ETX</td><td>End of Text</td></tr><tr><td>4</td><td>4</td><td>EOT</td><td>End of Transmission</td></tr><tr><td>5</td><td>5</td><td>ENQ</td><td>Enquiry</td></tr><tr><td>6</td><td>6</td><td>ACK</td><td>Acknowledge</td></tr><tr><td>7</td><td>7</td><td>BEL</td><td>Звуковой сигнал</td></tr><tr><td>8</td><td>8</td><td>BS</td><td>Backspace</td></tr><tr><td>9</td><td>9</td><td>TAB</td><td>Горизонтальная табуляция</td></tr><tr><td>10</td><td>0A</td><td>LF</td><td>Перевод строки</td></tr><tr><td>11</td><td>0B</td><td>VT</td><td>Вертикальная табуляция</td></tr><tr><td>12</td><td>0C</td><td>FF</td><td>Прогон страницы</td></tr><tr><td>13</td><td>0D</td><td>CR</td><td>Возврат каретки</td></tr><tr><td>14</td><td>0E</td><td>SO</td><td>Shift Out</td></tr><tr><td>15</td><td>0F</td><td>SI</td><td>Shift In</td></tr><tr><td>16–31</td><td>10–1F</td><td>—</td><td>Управляющие коды</td></tr><tr><td>32</td><td>20</td><td>(Space)</td><td>Пробел</td></tr><tr><td>33–47</td><td>21–2F</td><td>! " # $ % & ' ( ) * + , - . /</td><td>Знаки препинания</td></tr><tr><td>48–57</td><td>30–39</td><td>0–9</td><td>Цифры</td></tr><tr><td>58–64</td><td>3A–40</td><td>: ; < = > ? @</td><td>Символы</td></tr><tr><td>65–90</td><td>41–5A</td><td>A–Z</td><td>Заглавные буквы</td></tr><tr><td>91–96</td><td>5B–60</td><td>[ \ ] ^ _ `</td><td>Скобки и служебные</td></tr><tr><td>97–122</td><td>61–7A</td><td>a–z</td><td>Строчные буквы</td></tr><tr><td>123–126</td><td>7B–7E</td><td>{</td><td>} ~</td></tr><tr><td>127</td><td>7F</td><td>DEL</td><td>Удаление</td></tr></tbody></table></div></div></div></div>
<p>Эта таблица образует минимальный набор символов, поддерживаемый всеми системами без исключения.</p>
<h2 id="heading-2-26">Преимущества и ограничения ASCII</h2>
<p>После десятилетий использования ASCII остаётся одним из самых устойчивых стандартов в сфере информационных технологий. Его принципы просты, но именно эта простота обеспечила долговечность и совместимость с современными системами. При этом у стандарта есть объективные пределы, обусловленные историческими ограничениями его разработки. Рассмотрим сильные стороны и недостатки ASCII с позиции современного ИТ-контекста.</p>
<h3 id="heading-3-27">Преимущества</h3>
<ul>
<li>
<p>Простая структура и лёгкая реализация.</p>
</li>
<li>
<p>Полная совместимость между устройствами, операционными системами и протоколами.</p>
</li>
<li>
<p>Небольшой объём данных — каждый символ занимает 1 байт.</p>
</li>
<li>
<p>Надёжность и устойчивость при передаче информации в любых сетях.</p>
</li>
<li>
<p>Базовая совместимость с Unicode и его подмножествами (первые 128 кодов полностью совпадают).</p>
</li>
</ul>
<p>Благодаря этим свойствам ASCII до сих пор используется как внутренний формат системных утилит, терминалов, микроконтроллеров и текстовых протоколов, где минимализм и предсказуемость критически важны.</p>
<h3 id="heading-3-28">Ограничения</h3>
<ul>
<li>
<p>Всего 128 символов — недостаточно для национальных алфавитов и расширенных наборов знаков.</p>
</li>
<li>
<p>Отсутствие поддержки диакритики, символов валют, графических элементов и специальных обозначений.</p>
</li>
<li>
<p>Невозможность прямого применения в многоязычных и контентных системах.</p>
</li>
<li>
<p>Проблемы совместимости при переходе на расширенные версии и другие локальные кодировки.</p>
</li>
</ul>
<p>Несмотря на это, ASCII остаётся основой большинства современных текстовых форматов. Такие технологии, как HTML, XML, JSON, CSV, используют ASCII в качестве базового слоя представления данных, а Unicode — лишь как надстройку для дополнительных символов. Это доказывает, что даже в эпоху глобальных стандартов минимализм ASCII продолжает обеспечивать стабильность цифрового обмена.</p></div><div class="m_3eebeb36 mantine-Divider-root" data-orientation="horizontal" role="separator"></div><div style="--group-gap:var(--mantine-spacing-md);--group-align:center;--group-justify:flex-start;--group-wrap:wrap;font-size:var(--mantine-font-size-sm)" class="m_4081bf90 mantine-Group-root"><div style="--group-gap:var(--mantine-spacing-xs);--group-align:center;--group-justify:flex-start;--group-wrap:wrap;margin-inline-start:auto" class="m_4081bf90 mantine-Group-root"><svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="1.2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-calendar "><path d="M4 7a2 2 0 0 1 2 -2h12a2 2 0 0 1 2 2v12a2 2 0 0 1 -2 2h-12a2 2 0 0 1 -2 -2v-12"></path><path d="M16 3v4"></path><path d="M8 3v4"></path><path d="M4 11h16"></path><path d="M11 15h1"></path><path d="M12 15v3"></path></svg><p class="mantine-focus-auto m_b6d8b162 mantine-Text-root" data-inherit="true">3 месяца назад</p></div><div style="--group-gap:var(--mantine-spacing-xs);--group-align:center;--group-justify:flex-start;--group-wrap:wrap" class="m_4081bf90 mantine-Group-root"><svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="1.2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-user "><path d="M8 7a4 4 0 1 0 8 0a4 4 0 0 0 -8 0"></path><path d="M6 21v-2a4 4 0 0 1 4 -4h4a4 4 0 0 1 4 4v2"></path></svg><p class="mantine-focus-auto m_b6d8b162 mantine-Text-root" data-inherit="true">Nikolai Gagarinov</p></div></div></div></div></div><div style="margin-bottom:var(--mantine-spacing-xl);padding:var(--mantine-spacing-lg)" class="m_e615b15f mantine-Card-root m_1b7284a3 mantine-Paper-root" data-with-border="true" id="answer-3301"><div style="--group-gap:calc(1.125rem * var(--mantine-scale));--group-align:stretch;--group-justify:flex-start;--group-wrap:nowrap" class="m_4081bf90 mantine-Group-root"><div style="--stack-gap:var(--mantine-spacing-md);--stack-align:stretch;--stack-justify:flex-start;font-size:var(--mantine-font-size-h1);font-weight:lighter;text-align:center" class="m_6d731127 mantine-Stack-root">0<a style="color:inherit" class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/qna/glossary/questions/chto-takoe-ascii/answers/3301/vote"><div style="--ti-bg:transparent;--ti-color:var(--mantine-color-indigo-light-color);--ti-bd:calc(0.0625rem * var(--mantine-scale)) solid transparent;color:inherit" class="m_7341320d mantine-ThemeIcon-root" data-variant="transparent"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-thumb-up "><path d="M7 11v8a1 1 0 0 1 -1 1h-2a1 1 0 0 1 -1 -1v-7a1 1 0 0 1 1 -1h3a4 4 0 0 0 4 -4v-1a2 2 0 0 1 4 0v5h3a2 2 0 0 1 2 2l-1 5a2 3 0 0 1 -2 2h-7a3 3 0 0 1 -3 -3"></path></svg></div></a></div><div style="--stack-gap:var(--mantine-spacing-md);--stack-align:stretch;--stack-justify:flex-start;width:100%;min-width:0rem" class="m_6d731127 mantine-Stack-root"><div style="margin-bottom:auto" class="m_d08caa0 mantine-Typography-root"><p>ASCII (American Standard Code for Information Interchange) - это таблица символов, которая используется для представления букв, цифр и других символов в виде чисел. ASCII используется в большинстве компьютерных систем и является основой для других кодировок, таких как UTF-8 и UTF-16.</p></div><div class="m_3eebeb36 mantine-Divider-root" data-orientation="horizontal" role="separator"></div><div style="--group-gap:var(--mantine-spacing-md);--group-align:center;--group-justify:flex-start;--group-wrap:wrap;font-size:var(--mantine-font-size-sm)" class="m_4081bf90 mantine-Group-root"><div style="--group-gap:var(--mantine-spacing-xs);--group-align:center;--group-justify:flex-start;--group-wrap:wrap;margin-inline-start:auto" class="m_4081bf90 mantine-Group-root"><svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="1.2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-calendar "><path d="M4 7a2 2 0 0 1 2 -2h12a2 2 0 0 1 2 2v12a2 2 0 0 1 -2 2h-12a2 2 0 0 1 -2 -2v-12"></path><path d="M16 3v4"></path><path d="M8 3v4"></path><path d="M4 11h16"></path><path d="M11 15h1"></path><path d="M12 15v3"></path></svg><p class="mantine-focus-auto m_b6d8b162 mantine-Text-root" data-inherit="true">2 года назад</p></div><div style="--group-gap:var(--mantine-spacing-xs);--group-align:center;--group-justify:flex-start;--group-wrap:wrap" class="m_4081bf90 mantine-Group-root"><svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="1.2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-user "><path d="M8 7a4 4 0 1 0 8 0a4 4 0 0 0 -8 0"></path><path d="M6 21v-2a4 4 0 0 1 4 -4h4a4 4 0 0 1 4 4v2"></path></svg><p class="mantine-focus-auto m_b6d8b162 mantine-Text-root" data-inherit="true">Елена Редькина</p></div></div></div></div></div><style data-mantine-styles="inline">.__m__-_R_4bbdiub_{--carousel-slide-gap:var(--mantine-spacing-xs);--carousel-slide-size:70%;}@media(min-width: 36em){.__m__-_R_4bbdiub_{--carousel-slide-gap:var(--mantine-spacing-xl);--carousel-slide-size:50%;}}</style><div style="--carousel-control-size:calc(2.5rem * var(--mantine-scale));--carousel-controls-offset:var(--mantine-spacing-sm);margin-top:var(--mantine-spacing-xl);margin-bottom:var(--mantine-spacing-lg);padding-block:var(--mantine-spacing-sm);background:var(--app-color-surface)" class="m_17884d0f mantine-Carousel-root responsiveClassName" data-orientation="horizontal" data-include-gap-in-size="true"><div class="m_39bc3463 mantine-Carousel-controls" data-orientation="horizontal"><button class="mantine-focus-auto m_64f58e10 mantine-Carousel-control m_87cf2631 mantine-UnstyledButton-root" type="button" data-inactive="true" data-type="previous" tabindex="-1"><svg viewBox="0 0 15 15" fill="none" xmlns="http://www.w3.org/2000/svg" style="transform:rotate(90deg);width:calc(1rem * var(--mantine-scale));height:calc(1rem * var(--mantine-scale));display:block"><path d="M3.13523 6.15803C3.3241 5.95657 3.64052 5.94637 3.84197 6.13523L7.5 9.56464L11.158 6.13523C11.3595 5.94637 11.6759 5.95657 11.8648 6.15803C12.0536 6.35949 12.0434 6.67591 11.842 6.86477L7.84197 10.6148C7.64964 10.7951 7.35036 10.7951 7.15803 10.6148L3.15803 6.86477C2.95657 6.67591 2.94637 6.35949 3.13523 6.15803Z" fill="currentColor" fill-rule="evenodd" clip-rule="evenodd"></path></svg></button><button class="mantine-focus-auto m_64f58e10 mantine-Carousel-control m_87cf2631 mantine-UnstyledButton-root" type="button" data-inactive="true" data-type="next" tabindex="-1"><svg viewBox="0 0 15 15" fill="none" xmlns="http://www.w3.org/2000/svg" style="transform:rotate(-90deg);width:calc(1rem * var(--mantine-scale));height:calc(1rem * var(--mantine-scale));display:block"><path d="M3.13523 6.15803C3.3241 5.95657 3.64052 5.94637 3.84197 6.13523L7.5 9.56464L11.158 6.13523C11.3595 5.94637 11.6759 5.95657 11.8648 6.15803C12.0536 6.35949 12.0434 6.67591 11.842 6.86477L7.84197 10.6148C7.64964 10.7951 7.35036 10.7951 7.15803 10.6148L3.15803 6.86477C2.95657 6.67591 2.94637 6.35949 3.13523 6.15803Z" fill="currentColor" fill-rule="evenodd" clip-rule="evenodd"></path></svg></button></div><div class="m_a2dae653 mantine-Carousel-viewport" data-type="media"><div class="m_fcd81474 mantine-Carousel-container __m__-_R_4bbdiub_" data-orientation="horizontal"><div class="m_d98df724 mantine-Carousel-slide" data-orientation="horizontal"><div tabindex="0" style="cursor:pointer;height:100%"><a style="text-decoration:none" class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/programs/algorithms?promo_name=programs_list&promo_position=qna_question&promo_creative=catalog_card&promo_type=card" target="_blank"><div style="height:100%" class="m_e615b15f mantine-Card-root m_1b7284a3 mantine-Paper-root" data-with-border="true"><div style="--group-gap:calc(0.25rem * var(--mantine-scale));--group-align:center;--group-justify:flex-start;--group-wrap:nowrap" class="m_4081bf90 mantine-Group-root"><span style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">2 месяца</span><span class="mantine-focus-auto m_b6d8b162 mantine-Text-root">·</span><span style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Для продвинутых</span></div><p style="margin-bottom:var(--mantine-spacing-sm);font-size:var(--mantine-font-size-h5);font-weight:bold" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Алгоритмы и структуры данных</p><p class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Алгоритмы для собеседований</p><div style="margin-top:auto" class=""><div class="m_4451eb3a mantine-Center-root"><img style="opacity:0.8;width:70%" class="m_9e117634 mantine-Image-root mantine-visible-from-xs" src="https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6NDAyOCwicHVyIjoiYmxvYl9pZCJ9fQ==--ae9eed98663dd1201759d042a5ba7ca790866156/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Programming-bro.png" alt="Алгоритмы и структуры данных" loading="eager"/></div><div style="--group-gap:var(--mantine-spacing-md);--group-align:end;--group-justify:space-between;--group-wrap:wrap;margin-top:var(--mantine-spacing-xs)" class="m_4081bf90 mantine-Group-root"><p style="font-size:var(--mantine-font-size-xl)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">от 3 900 ₽</p><p style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Посмотреть →</p></div></div></div></a></div></div><div class="m_d98df724 mantine-Carousel-slide" data-orientation="horizontal"><div tabindex="0" style="cursor:pointer;height:100%"><a style="text-decoration:none" class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/programs/discrete-mathematics?promo_name=programs_list&promo_position=qna_question&promo_creative=catalog_card&promo_type=card" target="_blank"><div style="height:100%" class="m_e615b15f mantine-Card-root m_1b7284a3 mantine-Paper-root" data-with-border="true"><div style="--group-gap:calc(0.25rem * var(--mantine-scale));--group-align:center;--group-justify:flex-start;--group-wrap:nowrap" class="m_4081bf90 mantine-Group-root"><span style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">1 месяц</span><span class="mantine-focus-auto m_b6d8b162 mantine-Text-root">·</span><span style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">С нуля</span></div><p style="margin-bottom:var(--mantine-spacing-sm);font-size:var(--mantine-font-size-h5);font-weight:bold" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Дискретная математика</p><p class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Дискретная математика для программистов</p><div style="margin-top:auto" class=""><div class="m_4451eb3a mantine-Center-root"><img style="opacity:0.8;width:70%" class="m_9e117634 mantine-Image-root mantine-visible-from-xs" src="https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6MzY2MSwicHVyIjoiYmxvYl9pZCJ9fQ==--e9c2b6bde361adaac625a7f47d8b9671c17f3ddb/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Mathematics-bro.png" alt="Дискретная математика" loading="eager"/></div><div style="--group-gap:var(--mantine-spacing-md);--group-align:end;--group-justify:space-between;--group-wrap:wrap;margin-top:var(--mantine-spacing-xs)" class="m_4081bf90 mantine-Group-root"><p style="font-size:var(--mantine-font-size-xl)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">от 3 900 ₽</p><p style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Посмотреть →</p></div></div></div></a></div></div><div class="m_d98df724 mantine-Carousel-slide" data-orientation="horizontal"><div tabindex="0" style="cursor:pointer;height:100%"><a style="text-decoration:none" class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/programs/frontend?promo_name=programs_list&promo_position=qna_question&promo_creative=catalog_card&promo_type=card" target="_blank"><div style="height:100%" class="m_e615b15f mantine-Card-root m_1b7284a3 mantine-Paper-root" data-with-border="true"><div style="--group-gap:calc(0.25rem * var(--mantine-scale));--group-align:center;--group-justify:flex-start;--group-wrap:nowrap" class="m_4081bf90 mantine-Group-root"><span style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">10 месяцев</span><span class="mantine-focus-auto m_b6d8b162 mantine-Text-root">·</span><span style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">С нуля</span></div><p style="margin-bottom:var(--mantine-spacing-sm);font-size:var(--mantine-font-size-h5);font-weight:bold" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Фронтенд-разработчик</p><p class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Изучите HTML, CSS, JavaScript и React</p><div style="margin-top:auto" class=""><div class="m_4451eb3a mantine-Center-root"><img style="opacity:0.8;width:70%" class="m_9e117634 mantine-Image-root mantine-visible-from-xs" src="https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6MzcyNywicHVyIjoiYmxvYl9pZCJ9fQ==--2d5cbbf5c3b4a73ae4b2c50632305d78f5872e4d/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Programmer-rafiki.png" alt="Фронтенд-разработчик" loading="eager"/></div><div style="--group-gap:var(--mantine-spacing-md);--group-align:end;--group-justify:space-between;--group-wrap:wrap;margin-top:var(--mantine-spacing-xs)" class="m_4081bf90 mantine-Group-root"><p style="font-size:var(--mantine-font-size-xl)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">от 6 792 ₽</p><p style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Посмотреть →</p></div></div></div></a></div></div><div class="m_d98df724 mantine-Carousel-slide" data-orientation="horizontal"><div tabindex="0" style="cursor:pointer;height:100%"><a style="text-decoration:none" class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/programs/professional-layout?promo_name=programs_list&promo_position=qna_question&promo_creative=catalog_card&promo_type=card" target="_blank"><div style="height:100%" class="m_e615b15f mantine-Card-root m_1b7284a3 mantine-Paper-root" data-with-border="true"><div style="--group-gap:calc(0.25rem * var(--mantine-scale));--group-align:center;--group-justify:flex-start;--group-wrap:nowrap" class="m_4081bf90 mantine-Group-root"><span style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">5 месяцев</span><span class="mantine-focus-auto m_b6d8b162 mantine-Text-root">·</span><span style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">С нуля</span></div><p style="margin-bottom:var(--mantine-spacing-sm);font-size:var(--mantine-font-size-h5);font-weight:bold" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Профессиональная верстка</p><p class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Адаптивная вёрстка для отображения на любых устройствах </p><div style="margin-top:auto" class=""><div class="m_4451eb3a mantine-Center-root"><img style="opacity:0.8;width:70%" class="m_9e117634 mantine-Image-root mantine-visible-from-xs" src="https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6NDAzNCwicHVyIjoiYmxvYl9pZCJ9fQ==--ba516ea9573bdfcd1d21e2aa0fff8818561828f2/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Typing-bro.png" alt="Профессиональная верстка" loading="eager"/></div><div style="--group-gap:var(--mantine-spacing-md);--group-align:end;--group-justify:space-between;--group-wrap:wrap;margin-top:var(--mantine-spacing-xs)" class="m_4081bf90 mantine-Group-root"><p style="font-size:var(--mantine-font-size-xl)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">от 3 900 ₽</p><p style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Посмотреть →</p></div></div></div></a></div></div><div class="m_d98df724 mantine-Carousel-slide" data-orientation="horizontal"><div tabindex="0" style="cursor:pointer;height:100%"><a style="text-decoration:none" class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/programs/java?promo_name=programs_list&promo_position=qna_question&promo_creative=catalog_card&promo_type=card" target="_blank"><div style="height:100%" class="m_e615b15f mantine-Card-root m_1b7284a3 mantine-Paper-root" data-with-border="true"><div style="--group-gap:calc(0.25rem * var(--mantine-scale));--group-align:center;--group-justify:flex-start;--group-wrap:nowrap" class="m_4081bf90 mantine-Group-root"><span style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">10 месяцев</span><span class="mantine-focus-auto m_b6d8b162 mantine-Text-root">·</span><span style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">С нуля</span></div><p style="margin-bottom:var(--mantine-spacing-sm);font-size:var(--mantine-font-size-h5);font-weight:bold" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Java-разработчик</p><p class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Изучите Java и фреймворк Spring Boot и REST API</p><div style="margin-top:auto" class=""><div class="m_4451eb3a mantine-Center-root"><img style="opacity:0.8;width:70%" class="m_9e117634 mantine-Image-root mantine-visible-from-xs" src="https://hexlet.io/rails/active_storage/representations/proxy/eyJfcmFpbHMiOnsiZGF0YSI6MzczNSwicHVyIjoiYmxvYl9pZCJ9fQ==--883f3fd4e1b571538035b5680c8d4a9eb504b1f6/eyJfcmFpbHMiOnsiZGF0YSI6eyJmb3JtYXQiOiJ3ZWJwIiwicmVzaXplX3RvX2xpbWl0IjpbNDAwLDQwMF0sInNhdmVyIjp7InF1YWxpdHkiOjg1fX0sInB1ciI6InZhcmlhdGlvbiJ9fQ==--5b6f46dacd1af664f27558553a58076185091823/Source%20code-amico.png" alt="Java-разработчик" loading="eager"/></div><div style="--group-gap:var(--mantine-spacing-md);--group-align:end;--group-justify:space-between;--group-wrap:wrap;margin-top:var(--mantine-spacing-xs)" class="m_4081bf90 mantine-Group-root"><p style="font-size:var(--mantine-font-size-xl)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">от 6 792 ₽</p><p style="font-size:var(--mantine-font-size-sm)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Посмотреть →</p></div></div></div></a></div></div><div class="m_d98df724 mantine-Carousel-slide" data-orientation="horizontal"><div tabindex="0" style="cursor:pointer;height:100%"><a style="text-decoration:none" class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/courses?promo_name=programs_list&promo_position=qna_question&promo_creative=catalog_card&promo_type=card"><div style="height:100%" class="m_e615b15f mantine-Card-root m_1b7284a3 mantine-Paper-root" data-with-border="true"><h2 style="--title-fw:var(--mantine-h2-font-weight);--title-lh:var(--mantine-h2-line-height);--title-fz:var(--mantine-h2-font-size);margin-bottom:var(--mantine-spacing-md);font-size:var(--mantine-font-size-h3)" class="m_8a5d1357 mantine-Title-root" data-order="2" data-responsive="true">Каталог</h2><p style="margin-bottom:auto" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Полный список доступных курсов по разным направлениям</p><div style="margin-top:auto" class=""><div class="m_4451eb3a mantine-Center-root"><img style="opacity:0.8;width:70%" class="m_9e117634 mantine-Image-root mantine-visible-from-xs" src="/vite/assets/development-BVihs_d5.png" alt="Orientation"/></div></div></div></a></div></div></div></div></div></div><style data-mantine-styles="inline">.__m__-_R_5diub_{--col-flex-grow:auto;--col-flex-basis:100%;--col-max-width:100%;}@media(min-width: 48em){.__m__-_R_5diub_{--col-flex-grow:auto;--col-flex-basis:16.666666666666668%;--col-max-width:16.666666666666668%;}}@media(min-width: 62em){.__m__-_R_5diub_{--col-flex-grow:auto;--col-flex-basis:33.333333333333336%;--col-max-width:33.333333333333336%;}}</style><div class="m_96bdd299 mantine-Grid-col __m__-_R_5diub_ mantine-visible-from-md"><div style="margin-bottom:var(--mantine-spacing-xl);padding:var(--mantine-spacing-xl);background:var(--mantine-color-blue-0);width:100%" class="m_e615b15f mantine-Card-root m_1b7284a3 mantine-Paper-root"><p style="margin-bottom:var(--mantine-spacing-sm);font-size:var(--mantine-font-size-h4)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Похожие вопросы</p><ul class="m_abbac491 mantine-List-root"><li style="margin-bottom:var(--mantine-spacing-xs)" class="m_abb6bec2 mantine-List-item" data-with-icon="true"><div class="m_75cd9f71 mantine-List-itemWrapper"><span class="m_60f83e5b mantine-List-itemIcon"><div class="m_4451eb3a mantine-Center-root"><div style="--ti-size:var(--ti-size-xs);--ti-bg:transparent;--ti-color:var(--mantine-color-indigo-light-color);--ti-bd:calc(0.0625rem * var(--mantine-scale)) solid transparent;color:inherit" class="m_7341320d mantine-ThemeIcon-root" data-variant="transparent" data-size="xs"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-chevron-compact-right "><path d="M11 4l3 8l-3 8"></path></svg></div></div></span><span class="mantine-List-itemLabel"><a class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/qna/glossary/questions/chto-takoe-pandas">Pandas</a></span></div></li><li style="margin-bottom:var(--mantine-spacing-xs)" class="m_abb6bec2 mantine-List-item" data-with-icon="true"><div class="m_75cd9f71 mantine-List-itemWrapper"><span class="m_60f83e5b mantine-List-itemIcon"><div class="m_4451eb3a mantine-Center-root"><div style="--ti-size:var(--ti-size-xs);--ti-bg:transparent;--ti-color:var(--mantine-color-indigo-light-color);--ti-bd:calc(0.0625rem * var(--mantine-scale)) solid transparent;color:inherit" class="m_7341320d mantine-ThemeIcon-root" data-variant="transparent" data-size="xs"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-chevron-compact-right "><path d="M11 4l3 8l-3 8"></path></svg></div></div></span><span class="mantine-List-itemLabel"><a class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/qna/glossary/questions/chto-takoe-1c-buhgalteriya">1C:Бухгалтерия</a></span></div></li><li style="margin-bottom:var(--mantine-spacing-xs)" class="m_abb6bec2 mantine-List-item" data-with-icon="true"><div class="m_75cd9f71 mantine-List-itemWrapper"><span class="m_60f83e5b mantine-List-itemIcon"><div class="m_4451eb3a mantine-Center-root"><div style="--ti-size:var(--ti-size-xs);--ti-bg:transparent;--ti-color:var(--mantine-color-indigo-light-color);--ti-bd:calc(0.0625rem * var(--mantine-scale)) solid transparent;color:inherit" class="m_7341320d mantine-ThemeIcon-root" data-variant="transparent" data-size="xs"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-chevron-compact-right "><path d="M11 4l3 8l-3 8"></path></svg></div></div></span><span class="mantine-List-itemLabel"><a class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/qna/glossary/questions/chto-takoe-1c-predpriyatie">1C:Предприятие</a></span></div></li><li style="margin-bottom:var(--mantine-spacing-xs)" class="m_abb6bec2 mantine-List-item" data-with-icon="true"><div class="m_75cd9f71 mantine-List-itemWrapper"><span class="m_60f83e5b mantine-List-itemIcon"><div class="m_4451eb3a mantine-Center-root"><div style="--ti-size:var(--ti-size-xs);--ti-bg:transparent;--ti-color:var(--mantine-color-indigo-light-color);--ti-bd:calc(0.0625rem * var(--mantine-scale)) solid transparent;color:inherit" class="m_7341320d mantine-ThemeIcon-root" data-variant="transparent" data-size="xs"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-chevron-compact-right "><path d="M11 4l3 8l-3 8"></path></svg></div></div></span><span class="mantine-List-itemLabel"><a class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/qna/glossary/questions/chto-takoe-a-b-testirovanie">A/B-тестирование</a></span></div></li><li style="margin-bottom:var(--mantine-spacing-xs)" class="m_abb6bec2 mantine-List-item" data-with-icon="true"><div class="m_75cd9f71 mantine-List-itemWrapper"><span class="m_60f83e5b mantine-List-itemIcon"><div class="m_4451eb3a mantine-Center-root"><div style="--ti-size:var(--ti-size-xs);--ti-bg:transparent;--ti-color:var(--mantine-color-indigo-light-color);--ti-bd:calc(0.0625rem * var(--mantine-scale)) solid transparent;color:inherit" class="m_7341320d mantine-ThemeIcon-root" data-variant="transparent" data-size="xs"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="tabler-icon tabler-icon-chevron-compact-right "><path d="M11 4l3 8l-3 8"></path></svg></div></div></span><span class="mantine-List-itemLabel"><a class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/qna/glossary/questions/chto-takoe-agile">Agile</a></span></div></li></ul></div><div style="justify-content:end;margin-top:0rem;position:sticky;top:calc(5rem * var(--mantine-scale))" class="m_8bffd616 mantine-Flex-root __m__-_R_1bddiub_"><div tabindex="0" style="cursor:pointer"><a style="text-decoration:none" class="mantine-focus-auto m_849cf0da m_b6d8b162 mantine-Text-root mantine-Anchor-root" data-underline="hover" href="/courses_web_development?promo_name=program_category&promo_position=qna_question&promo_creative=card&promo_type=card"><div style="background-color:var(--mantine-color-default);border:calc(0.0625rem * var(--mantine-scale)) solid var(--mantine-color-default-border);padding-inline:var(--mantine-spacing-xl);padding-top:var(--mantine-spacing-xl);padding-bottom:var(--mantine-spacing-xs);width:100%" class="m_e615b15f mantine-Card-root m_1b7284a3 mantine-Paper-root"><div class="m_4451eb3a mantine-Center-root" data-inline="true"><p style="font-size:var(--mantine-font-size-h4)" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Курсы по веб-разработке</p></div><img class="m_9e117634 mantine-Image-root" src="/vite/assets/development-BVihs_d5.png"/><p style="margin-bottom:var(--mantine-spacing-xs);text-align:right" class="mantine-focus-auto m_b6d8b162 mantine-Text-root">Посмотреть →</p></div></a></div></div></div></div></div></div></div>
</main>
<footer class="bg-dark fw-light text-light px-3 py-5">
<div class="row small">
<div class="col-12 col-sm-6 col-md-3">
<div class="h5 mb-3">Хекслет</div>
<ul class="list-unstyled">
<li>
<a class="nav-link link-light py-1 ps-0" href="/pages/about">О нас</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/testimonials">Отзывы</a>
</li>
<li>
<span class="nav-link link-light py-1 ps-0 external-link" data-href="https://b2b.hexlet.io" role="button">Корпоративное обучение</span>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/blog">Блог</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/qna">Вопросы и ответы</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/glossary">Глоссарий</a>
</li>
<li>
<span class="nav-link link-light py-1 ps-0 external-link" data-href="https://help.hexlet.io" data-target="_blank" role="button">Справка</span>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" target="_blank" rel="noopener noreferrer" href="/map">Карта сайта</a>
</li>
</ul>
</div>
<div class="col-12 col-sm-6 col-md-3">
<div class="h5 fw-normal mb-3">Направления</div>
<ul class="list-unstyled">
<li>
<a class="nav-link link-light py-1 ps-0" href="/courses_devops">DevOps
</a></li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/courses_data_analytics">Аналитика
</a></li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/courses_backend_development">Бэкенд
</a></li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/courses_programming">Программирование
</a></li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/courses_testing">Тестирование
</a></li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/courses_front_end_dev">Фронтенд
</a></li>
</ul>
</div>
<div class="col-12 col-sm-6 col-md-3">
<div class="h5">Профессии</div>
<ul class="list-unstyled">
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/devops-engineer-from-scratch">DevOps-инженер с нуля</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/go">Go-разработчик</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/java">Java-разработчик</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/python">Python-разработчик </a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/data-analytics">Аналитик данных</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/qa-engineer">Инженер по ручному тестированию</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/php">РНР-разработчик</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/frontend">Фронтенд-разработчик</a>
</li>
</ul>
</div>
<div class="col-12 col-sm-6 col-md-3">
<div class="h5">Навыки</div>
<ul class="list-unstyled">
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/python-django-developer">Django</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/docker">Docker</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/php-laravel-developer">Laravel</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/postman">Postman</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/js-react-developer">React</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/js-rest-api">REST API в Node.js</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/spring-boot">Spring Boot</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/programs/typescript">Typescript</a>
</li>
</ul>
</div>
</div>
<hr>
<div class="row">
<div class="col-12 col-sm-4 col-md-2">
<div class="fs-4">
<ul class="list-unstyled d-flex">
<li class="me-3">
<a aria-label="Telegram" target="_blank" class="link-light" rel="noopener noreferrer nofollow" href="https://t.me/hexlet_ru"><span class="bi bi-telegram"></span>
</a></li>
<li>
<a aria-label="Youtube" target="_blank" class="link-light" rel="noopener noreferrer nofollow" href="https://www.youtube.com/user/HexletUniversity"><span class="bi bi-youtube"></span>
</a></li>
</ul>
</div>
<div class="mb-2 d-flex flex-column">
<a class="link-light text-decoration-none" rel="nofollow" href="mailto:support@hexlet.io">support@hexlet.io</a>
<a class="link-light text-decoration-none py-2" target="_blank" href="https://t.me/hexlet_help_bot">t.me/hexlet_help_bot</a>
</div>
<ul class="list-unstyled d-flex">
<li class="me-3">
<span class="link-light text-decoration-none opacity-50 x-font-size-18 external-link" rel="nofollow" data-href="https://hexlet.io/locale/switch?new_locale=en" data-target="_self" role="button"><span class="my-auto">EN</span>
</span></li>
<li class="me-3">
<span class="link-light text-decoration-none opacity-50 x-font-size-18 opacity-100 external-link" rel="nofollow" data-href="https://ru.hexlet.io/locale/switch?new_locale=ru" data-target="_self" role="button"><span class="my-auto">RU</span>
</span></li>
<li class="me-3">
<span class="link-light text-decoration-none opacity-50 x-font-size-18 external-link" rel="nofollow" data-href="https://kz.hexlet.io/locale/switch?new_locale=kz" data-target="_self" role="button"><span class="my-auto">KZ</span>
</span></li>
</ul>
</div>
<div class="col-12 col-sm-4 col-md-3">
<ul class="list-unstyled fs-4">
<li class="mb-3">
<a class="link-light text-decoration-none" href="tel:8%20800%20100%2022%2047">8 800 100 22 47</a>
<span class="d-block opacity-50 small">бесплатно по РФ</span>
</li>
<li>
<a class="link-light text-decoration-none" href="tel:%2B7%20495%20085%2021%2062">+7 495 085 21 62</a>
<span class="d-block opacity-50 small">бесплатно по Москве</span>
</li>
</ul>
</div>
<div class="col-12 col-sm-4 col-md-3">
<div class="small mb-3">Образовательные услуги оказываются на основании Л035-01298-77/01989008 от 14.03.2025</div>
<ul class="list-unstyled small">
<li>
<a class="nav-link link-light py-1 ps-0" href="/pages/legal">Правовая информация</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/pages/offer">Оферта</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/pages/license">Лицензия</a>
</li>
<li>
<a class="nav-link link-light py-1 ps-0" href="/pages/contacts">Контакты</a>
</li>
</ul>
</div>
<div class="col-12 col-sm-12 col-md-4 small">
<div class="mb-2">
<div>ООО «<a href="/" class="text-decoration-none link-light">Хекслет Рус</a>»</div>
<div>108813 г. Москва, вн.тер.г. поселение Московский,</div>
<div>г. Московский, ул. Солнечная, д. 3А, стр. 1, помещ. 20Б/3</div>
<div>ОГРН 1217300010476</div>
<div>ИНН 7325174845</div>
</div>
<hr>
<div>АНО ДПО «<a href="/" class="text-decoration-none link-light">Учебный центр «Хекслет</a>»</div>
<div>119331 г. Москва, вн. тер. г. муниципальный округ</div>
<div>Ломоносовский, пр-кт Вернадского, д. 29</div>
<div>ОГРН 1247700712390</div>
<div>ИНН 7736364948</div>
</div>
</div>
</footer>
<div id="root-assistant-offcanvas"></div>
<script src="/vite/assets/assistant-Bukl1lYy.js" crossorigin="anonymous" type="module"></script><link rel="modulepreload" href="/vite/assets/chunk-DsPFFUou.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/init-BrRXra1y.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/ErrorFallbackBlock-naDSYSy9.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/MarkdownBlock-DbyKWoR_.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/gon-D3e4yh1x.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/mantine-CGMYrt2Y.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/shiki-V011pkdv.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/utils-DRqSHbQE.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/routes-CCH8ilKF.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/lib-XR8Qr8kR.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/dist-GCHh59xr.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/Box-B5-OOzBf.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/notifications.store-C-3AFSMn.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/useIsomorphicEffect-HJ6VK0D3.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/lib-KSp6QbZ0.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/axios-BEvgo0ym.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/classnames-l6ipYlLR.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/dayjs.min-BkKovM-s.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/debounce-jMQ_Cf4f.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/i18next-BlSq9s7B.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/client-U9M77rxp.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/react-dom-DaLxUz_h.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/useTranslation-Bx1Cdrkz.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/compiler-runtime-6XxiPFnt.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/jsx-runtime-CwjcCKJi.js" as="script" crossorigin="anonymous">
<link rel="modulepreload" href="/vite/assets/react-CkL4ZRHB.js" as="script" crossorigin="anonymous">
<script defer src="https://static.cloudflareinsights.com/beacon.min.js/v67327c56f0bb4ef8b305cae61679db8f1769101564043" integrity="sha512-rdcWY47ByXd76cbCFzznIcEaCN71jqkWBBqlwhF1SY7KubdLKZiEGeP7AyieKZlGP9hbY/MhGrwXzJC/HulNyg==" data-cf-beacon='{"version":"2024.11.0","token":"d11015b65d11429ea6b4a2ef37dd7e0b","server_timing":{"name":{"cfCacheStatus":true,"cfEdge":true,"cfExtPri":true,"cfL4":true,"cfOrigin":true,"cfSpeedBrain":true},"location_startswith":null}}' crossorigin="anonymous"></script>
</body>
</html>